This is Lesson 1 of the Hands-on LLM Course, a FREE hands-on tutorial where you will learn, step-by-step, how to build a financial advisor, using LLMs and following MLOps best practices.
This course is not about building a demo inside a Jupyter notebook, but a fully working app, using the 3-pipeline design:
A fine-tuning pipeline that takes a base LLM and fine-tunes to our particular task.
A feature pipeline, that ingests in real-time financial news, generates vector embeddings and stores them in a VectorDB.
An inference pipeline, that takes in a user request, relevant context from the Vector DB, and returns sound financial advice using our fine-tuned LLM.
Today, we will learn how to build the fine-tuning pipeline.
Without further ado, let’s get started!
Why fine-tuning?
A fine-tuned LLMs on a specific task has 2 advantages over a generalist LLMs, like ChatGPT:
Better performance → A smaller, specialised LLM in a particular task works better than a generalist LLM (e.g. ChatGPT) with prompt engineering, for that particular task.
Cheaperto run → Smaller highly-specialized LLMs are cheaper to run, because they require less powerful hardware.
Now, how do you fine-tune an LLM in a real-world project?
Here are the 4 steps to fine-tune an open-source LLM to build our financial advisor.
1. Generate a dataset of (input, output) examples
You need to collect (or generate) a dataset of (Input, Output) pairs, where
input is the prompt you send to the model, and
output is what you expect the model to generate.
In our case, the input is made of 2 components:
an about_me section, where the user provides basic information about herself, and
a context that contains relevant financial news our LLM should use to provide sound investing advice.
💡 The dataset we use in this course was built following a semi-automatic approach, that I explained in this previous post. You can check the full code implementation here.
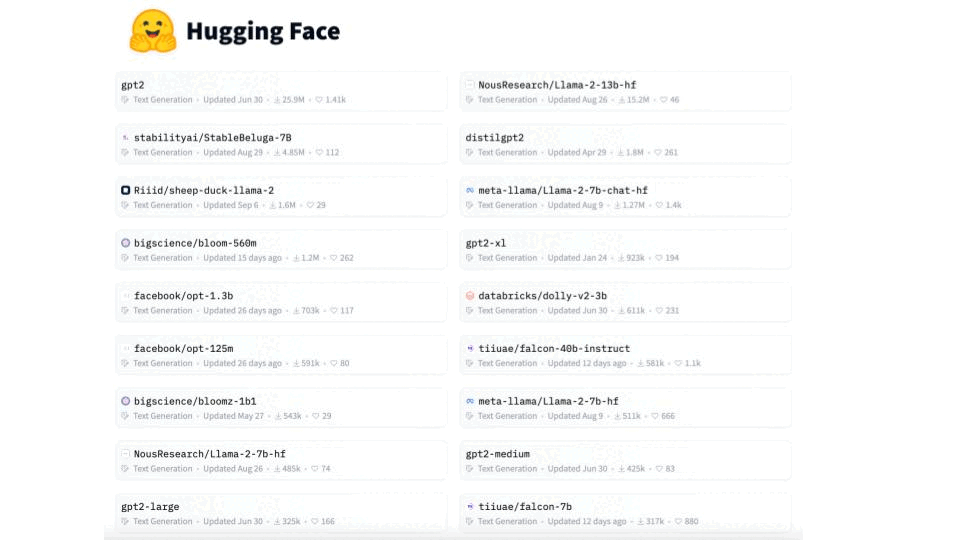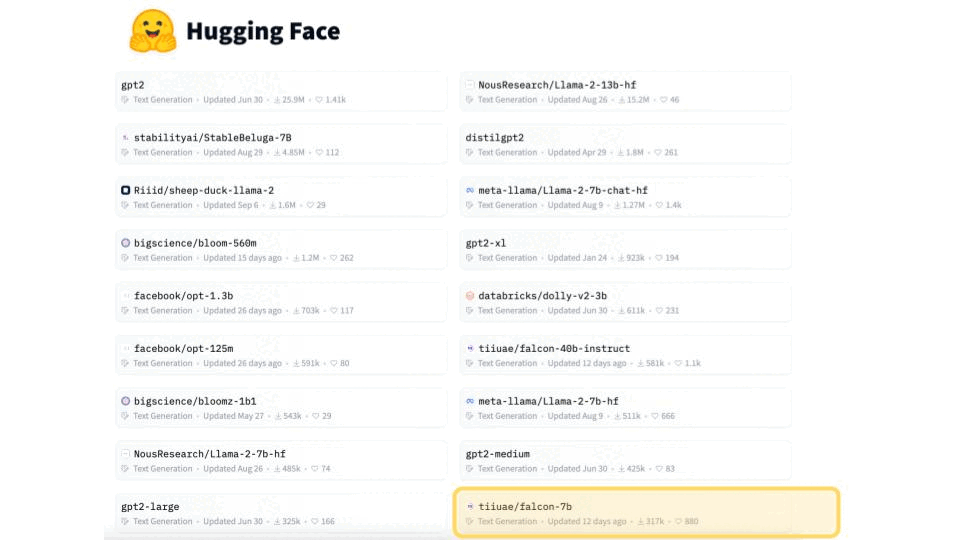
2. Choose an open-source base LLM
Hugging Face Models Hub contains a large collection of base LLMs. In this course, we use Falcon 7B, but feel free to choose a newer and better LLM, like Mistral 7B.
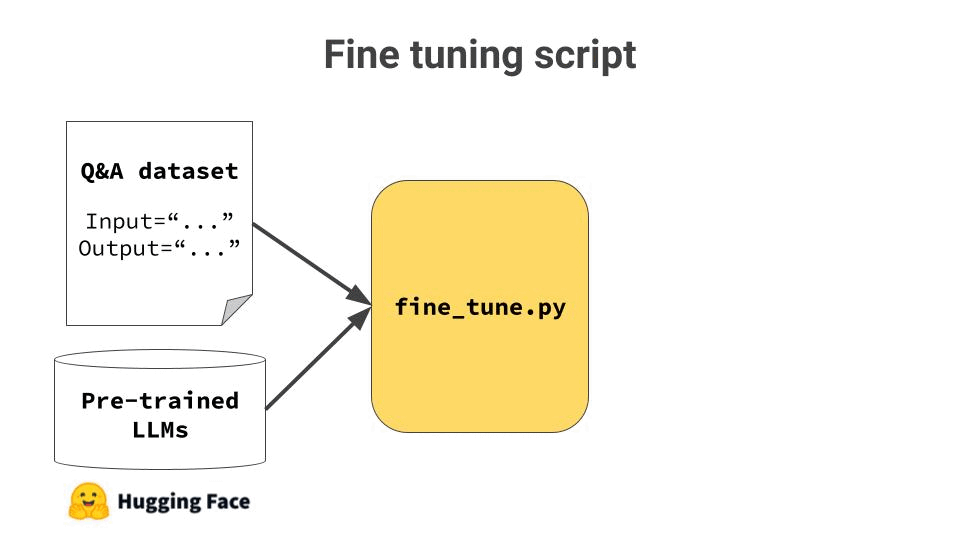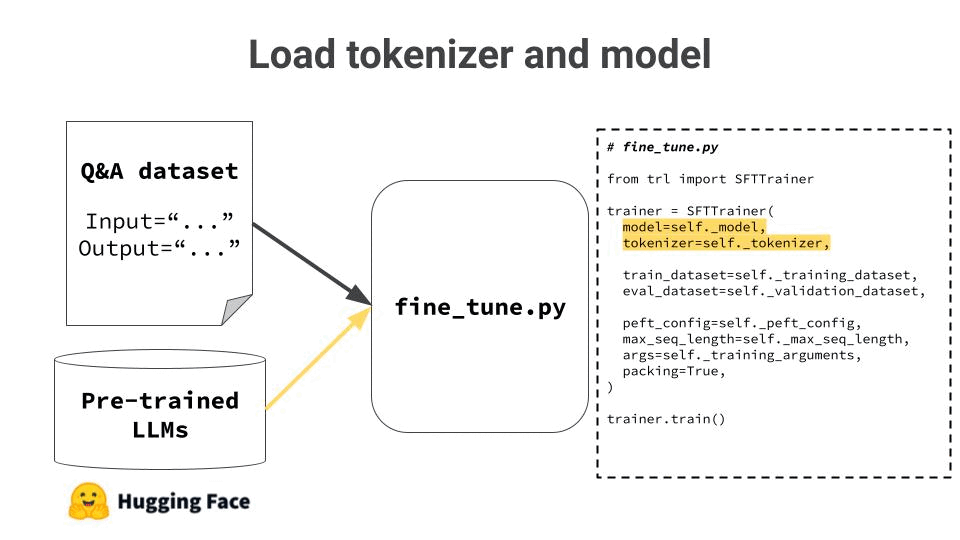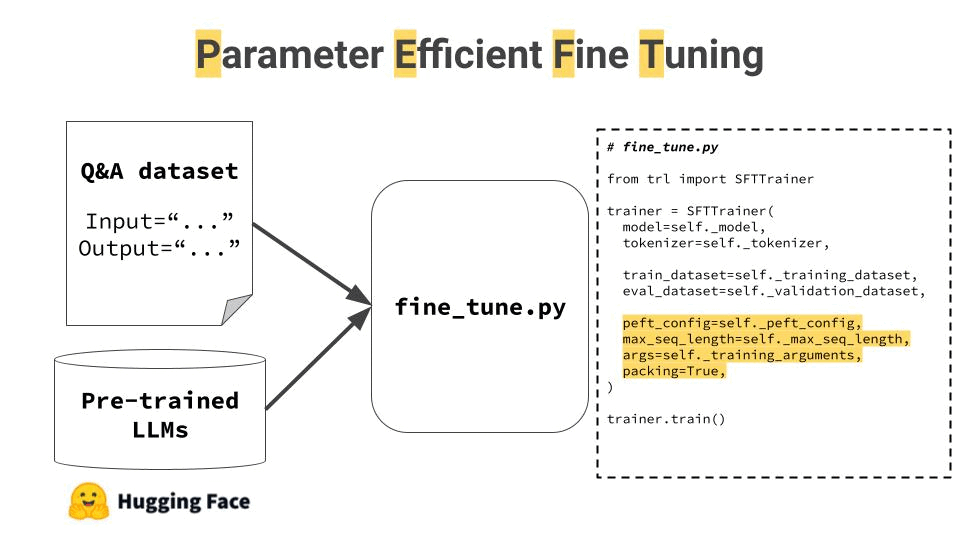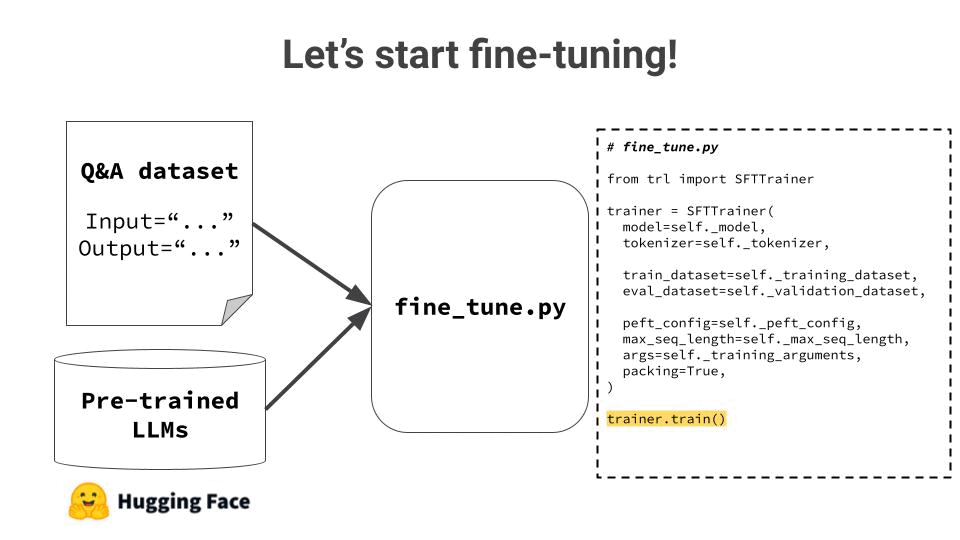
3. Run the Fine tuning script
The fine tuning script loads
→ the dataset from storage (e.g. S3 bucket), and → the model from Hugging Face
and kicks off the fine tuning algorithm.
We use the trl library by HuggingFace, that nicely wraps LoRA (Low-Rank Adapters) one of the most popular fine-tuning algorithms these days.
LoRA in a nutshell
With LoRA we don’t adjust any of the base LLM parameters. Instead, we add a small set of parameters to approximate the high-dimensional weight-matrices of the base LLM using PCA and Singular Value Decomposition.
My advice ✨
In practice, you need at least one GPU to run the fine tuning script. So, if you don’t have one, I recommend you use a Serverless computing platform like Beam. It is super simple:
1 → Sign up for FREE 2 → Get your API key 3 → Install the Beam SDK and integrate everything at the Python code (we will see how in the next lesson)
Voila! You now have access a remote GPU. And the first 10 hours of computing are for FREE.
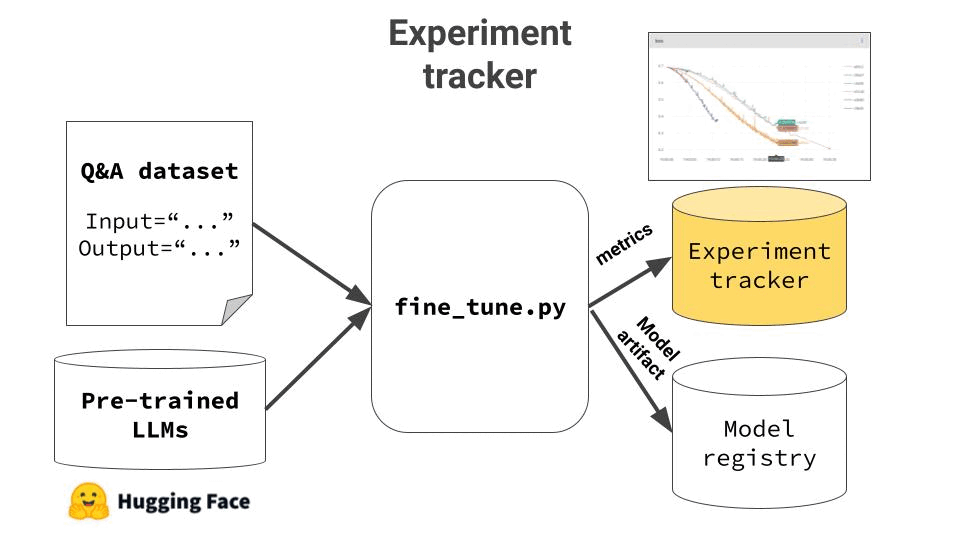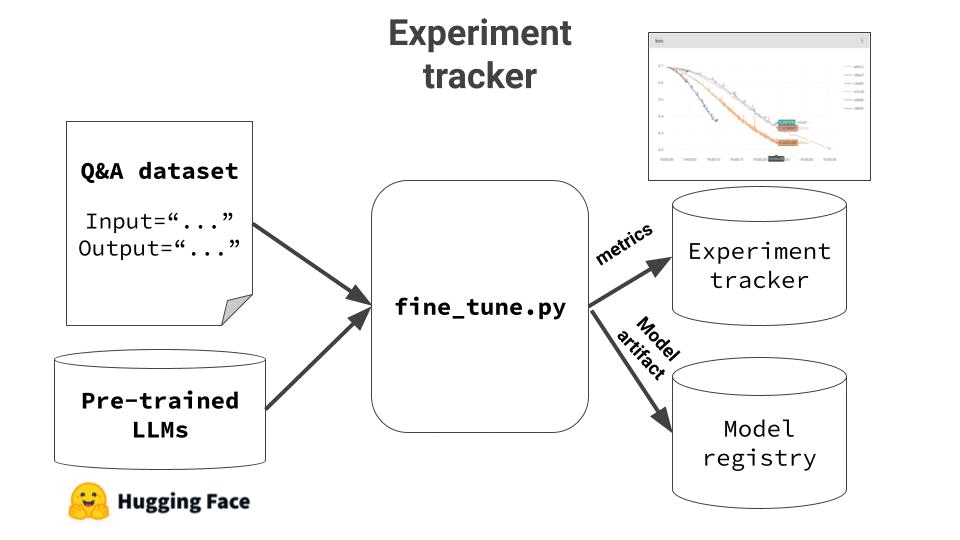
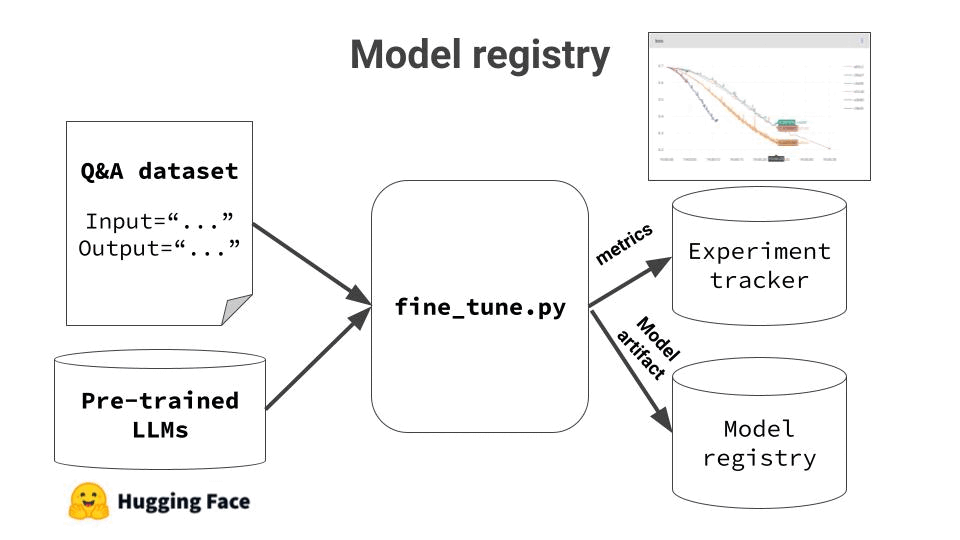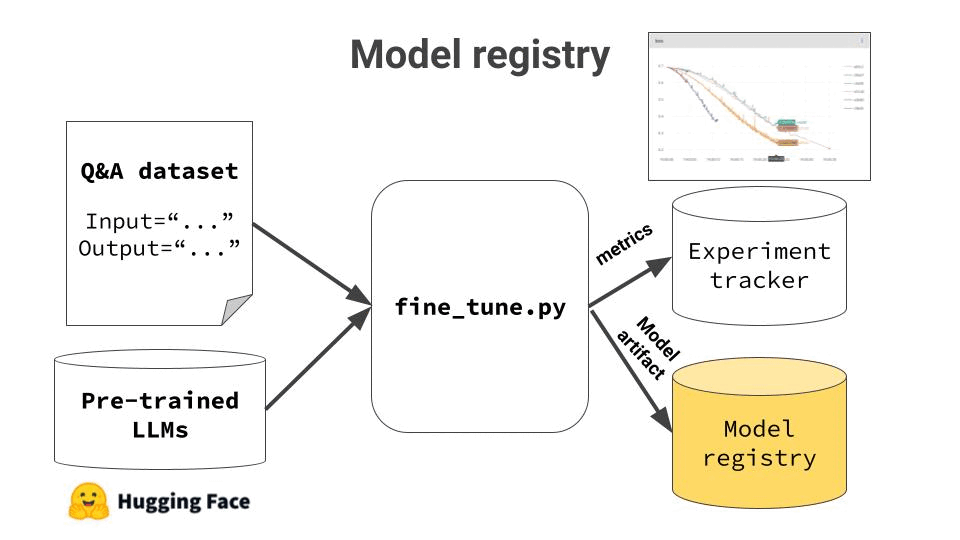
4. Log experiment results and model artifacts
Fine tuning is a very iterative process. You need to re-run the fine tuning script, with different input parameters (aka hyper-parameters) and keep track of the results. This is why I highly recommend adding an experiment tracker tool to your stack.
Finally, when you are happy with the results, you need to push the final model to the model registry, so you can painlessly deploy it later on.
My advice ✨
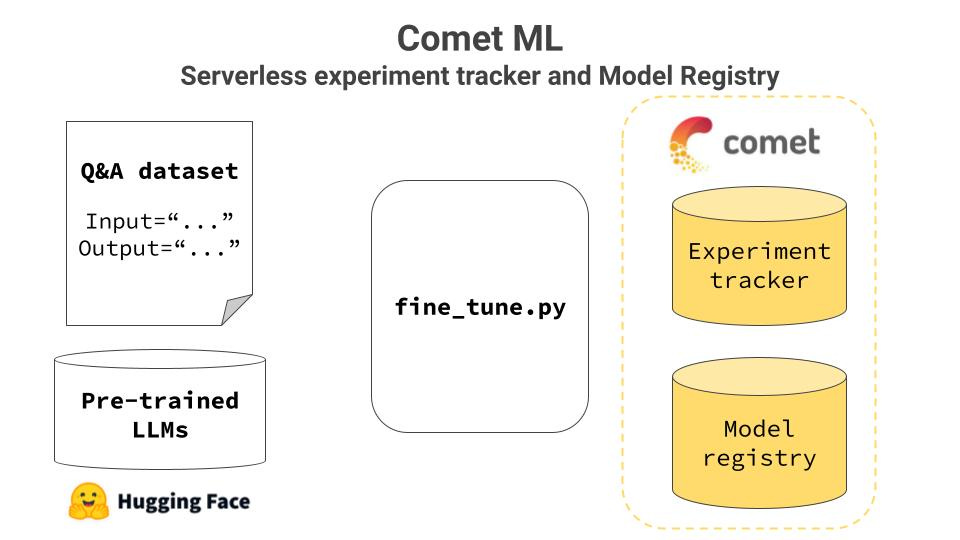
CometML is a Serverless Metadata platform, FREE for individuals like you and me, that includes a top-notch Experiment Tracker and Model Registry. Integrating it with you stack is as easy as
1 → Sign up for FREE 2 → Get you API key 3 → $ pip install comet_ml
Video lecture
All the video lectures are freely available on Youtube. Click below to watch it ↓
Really good my only comments are - do not to make assumptions about learner’s knowledge especially for beginners. For instance, all terms should be explained in case the learner is not familiar with them. E.g fine-tune, LoRa, CometML etc
Walk through setups with learners explaining each step as you progress. E.g run setup scripts for users to see and code line by like as you explain.




Really good my only comments are - do not to make assumptions about learner’s knowledge especially for beginners. For instance, all terms should be explained in case the learner is not familiar with them. E.g fine-tune, LoRa, CometML etc
Walk through setups with learners explaining each step as you progress. E.g run setup scripts for users to see and code line by like as you explain.