


How to generate a Q&A dataset in less than 30 minutes

Say you want to build an ML model that can act as an investing advisor. That is,
a user sends basic information about himself/herself
"I am a 25 year old software engineer with a stable income. I want to start investing in stocks for long-term growth. Where should I begin?",and the model returns sound financial advice
”Start by investing in a diversified portfolio of stocks across different sectors. Focus on tech stocks, as they have shown strong growth in recent years, but also consider investing in other sectors such as healthcare, energy, and consumer goods. Additionally, consider investing in index funds to spread out your risk and reduce volatility. Finally, consider investing in cryptocurrencies as well, as they can provide an additional layer of diversification and potential for growth."
What about LLM fine tuning?
One way to build such model is to
pick an open-source Large Language Model (e.g. Llama 2, Falcon 7B, etc.)
and fine-tune it for the specific task of providing investing advice.
However, before you can do this, you need to collect a dataset of (input, output) examples, where
input is the piece of text our users will send describing themselves and their investing goals, plus relevant financial news, and
output is what we want our model to respond, i.e. sound investing advice based on the user description, and the relevant news.
Now the question is
How do you generate this dataset?
Automatic generation of Q&A datasets with Large Language Models
Unless you have a team of financial experts that can bootstrap this dataset for you, you will need to get creative. This is the situation where I found myself 3 weeks ago, while working with Paul Iusztin on our Hands-on LLMOps free course.
And this is the solution Paul and I came up with.
Step 1. Manually generate a few input examples
Generate a few sample inputs with
An about_me written by the user that seeks investing advice, and
A context, that contains relevant financial news that the model should consider to justify its investing advice.
Here is one of the examples I generated manually:
{
"about_me": "I am a 28 year old marketing professional.\nI have some savings and I'm interested in crypto investments.\nIs Bitcoin a good investment option?",
"context": "El Salvador adopts Bitcoin as legal tender.\nRecent fluctuations in Bitcoin's price.\nRenewed interest from institutional investors."
},
Step 2. Expand this dataset with the help of an LLM
Let’s now use this small sample of inputs to generate similar ones with the help of a Large Language Model.
In this example we use OpenAI GPT-3.5 as our LLM, but feel free to use an open-source one, like Falcon, or Llama 2 🦙
To generate similar examples to the ones we already have, we construct the following prompt.
I will give you a sample prompt with an about me section and a context section. Can you generate 100 more examples following the same pattern? Please format the output as a Python list of dictionaries, with 2 keys: about_me and context
# ABOUT ME
I am a 21 year old college student.
I was thinking of investing in the stock market.
Is Meta a good stock to buy?
# CONTEXT
Meta fires 10k employes
Meta about to release Threads app
Zuckerberg to visit China soonAnd we got as a result a few more input examples:
[
{
"about_me": "I am a 28 year old marketing professional.\nI'm interested in diversifying my investment portfolio.\nWhat are your thoughts on investing in Bitcoin?",
"context": "Bitcoin experiences 15% price drop in the last week.\nElon Musk tweets about the environmental concerns of Bitcoin mining.\nThe Federal Reserve announces interest rate hike."
},
{
"about_me": "I am a 45 year old small business owner.\nI have some extra funds and I'm considering investing in tech stocks.\nWhat do you think about Amazon's future prospects?",
"context": "Amazon reports record-breaking Q2 revenue.\nRegulators announce increased scrutiny on big tech companies.\nJeff Bezos steps down as Amazon's CEO."
},
# ... (98 more examples)
]
Step 3. Ask the LLM to generate outputs for these inputs
We ask the LLM to generate sound investing advice for each (about_me, context) pair in our inputs list.
This is the prompt we used:
You are an expert in the stock and crypto markets. I will give you some information about myself and you will provide me with good investment advice.
# ABOUT ME
{ABOUT_ME}
# CONTEXT
{CONTEXT}
Please provide concrete advice in less than 100 tokens, and justify your answer based on the news provided in the context.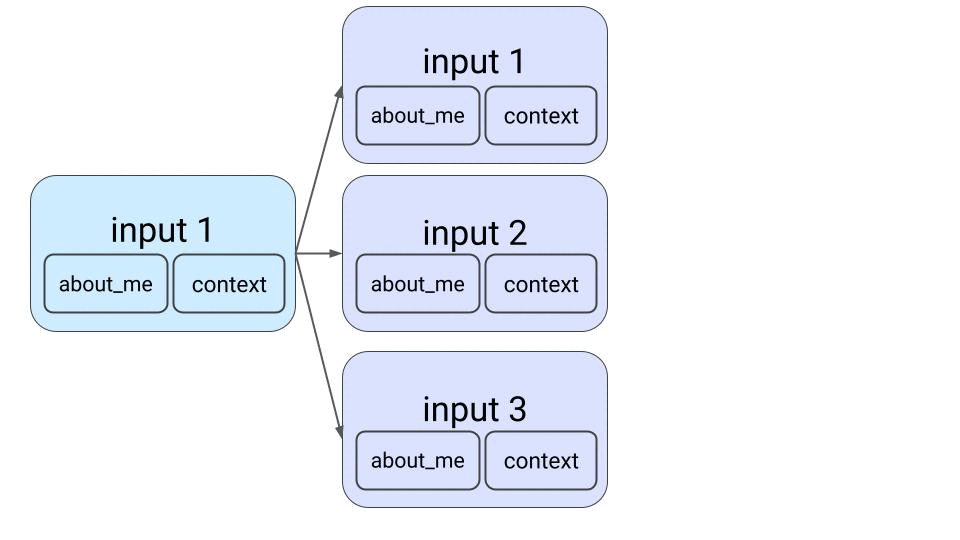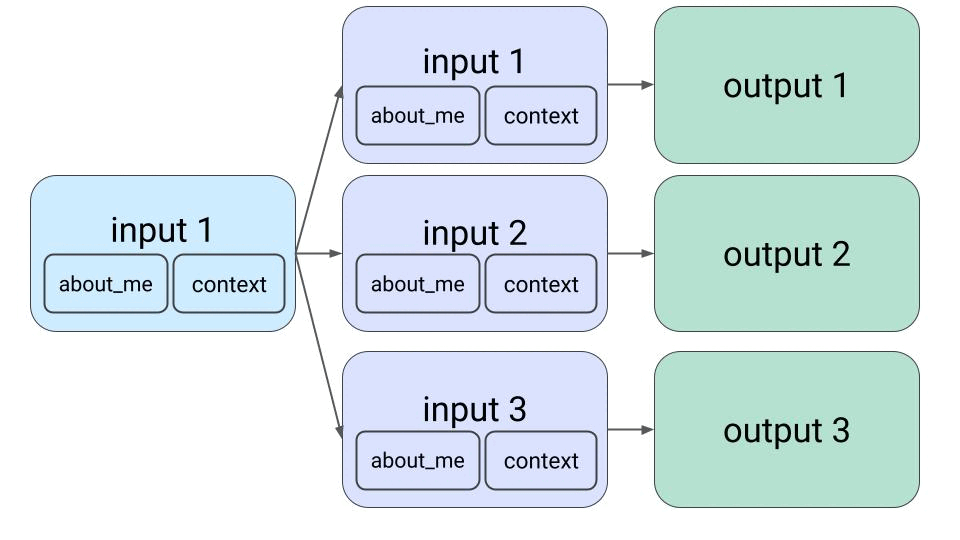
The final dataset we built consists of around 100 pairs (input, output) that you can find here.
BONUS: What about adding humans in the loop?
An even better way to generate training data would be to blend the generative power of the LLM with the expertise of a human investing advisor.
In this case, you would follow these 3 steps:
Manually generate a few sample inputs with (about_me, context)
Show these inputs to the human expert and ask her to provide the best investing advice possible (i.e. the best outputs)
Ask the LLM to generate more (input, output) that are similar to the ones you got from the human expert in the previous step. For that, you could use few-shot prompting.
LLMOps is very cool and all that…
…but before entering into LLMOps, I strongly recommend you get the grips with general ML and MLOps systems.
If you are looking for a hands-on, step-by-step tutorial, on how to build a complete ML app following MLOps best practices and design patterns, I recommend you enrol in The Real-World ML Tutorial.
🎁 Gift
Use this direct payment link until next Friday and get a massive 40% discount ($90 instead of $150)
➡️ Click here to read all the details
Have a great weekend
Let’s keep on learning,
Peace and Love
Pau