
How to Fine-tune a Large Language Model

Fine tuning is the process of adapting a base large language model (LLM), that was pre trained using a large corpus of raw text, to a specific task that has business value for you.
Example
Let’s take a base model like Falcon 7B and fine-tune it to create a new LLM that can act as an investing advisor in the stock market.
This model can later be deployed as a REST endpoint, where users send basic information about themselves and get solid investing advice.
Supervised fine-tuning of LLMs
The most common way to fine-tune a model is with supervised ML (there are other methods, like Reinforcement Learning with Human Feedback, aka RLHF, that we are not covering today).
In this case you need 3 ingredients:
1️⃣ A dataset of (input, output) examples
You need to collect a relevant dataset of (input, output) pairs, where
The input contains the person’s investing goals and some market context, and
The output is the investing advice that a human expert would give in this case, that we would like our model to generate.
As a rule of thumb, a dataset with 100+ works well in practice. If you have 1,000, even better. And if you have more, you are well covered.
2️⃣ A fine-tuning algorithm
Fine-tuning a pre-trained neural network is not a new technique in the AI/ML world. In computer vision, for example, it has been used for years to adjust convolutional deep neural networks, to specific datasets and downstream tasks.
The problem with LLMs however is that they have so many parameters, that
fine-tuning the entire network is prohibitively expensive
fine-tuning only the last layer of the network does not yield good results.
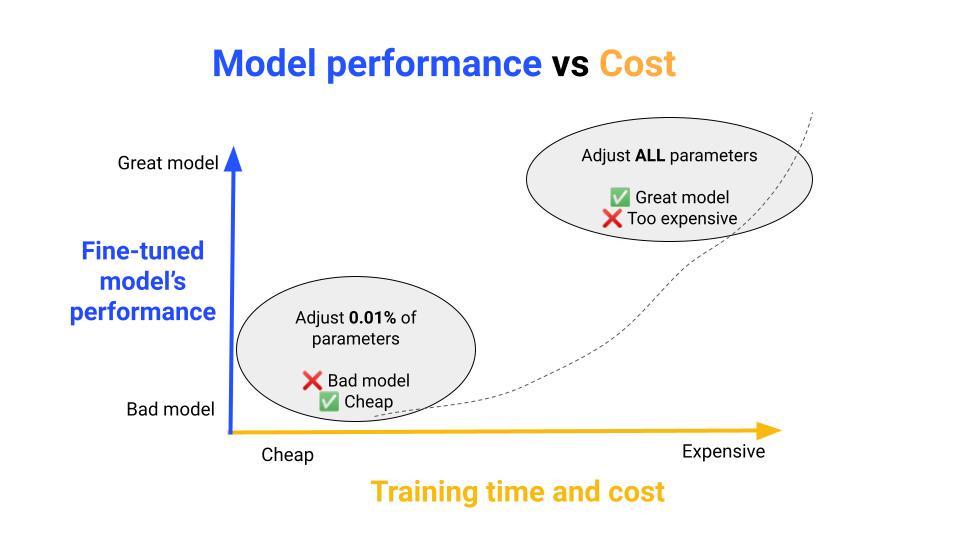
Because of this, the ML research community has come up with a new generation of fine-tuning algorithms that are more efficient (aka PEFT algorithms, Parameter Efficient Fine Tuning algorithms)
One of the most popular these days is LoRA (Low Rank Adaptation) which consists of
freezing the base LLM parameters, and
adding a small set of new trainable parameters, that are adjusted using batches of data and gradient descent.
PEFT by HuggingFace 🤗
In the last year, the open-source community has come up with great Python libraries that provide solid implementations of these algorithms, so you don’t need to implement them from scratch.
PEFT by Hugging Face is one of these, that I recommend you check out.
3️⃣ A GPU
Data and algorithms are great, but without having access to at least one GPU, you won’t get very far.
There are several options here:
Buy one. For example, the latest generation of MacBooks come with powerful GPus.
Use Google Colab, which is free but too limited to go beyond prototyping.
Rent an on-demand GPU instance on AWS, Google Cloud or Azure.
Use a serverless computing platform, like Beam, so you don’t need to manage and provision infrastructure.
Wanna learn to build a real-world product with LLMs?
Paul Iusztin and myself are building a new FREE course on LLMs, where you will learn step-by-step how to build an investing advisor using LLMs and MLOps best practices.
📣 This course is NOT about building yet another demo with LLMs, but a working product.
You will use a serverless stack to cover the entire MLOps workflow
Beam as the computing platform, to train and deploy our model.
Qdrant, to store vector embeddings and serve relevant context to our LLM.
Bytewax, to generate vector embeddings in real-time.
CometML to track experiments and prompts.
GitHub repo
Here is a link to the GitHub repo (Work In Progress), give it a star ⭐on GitHub to support our work 🙏
Have a great weekend,
Enjoy the journey
Pau
Nice topic and great explanation.👍🏽