
How to pass a technical interview for an AI role
Here's my story

Two weeks ago I started my first round of technical interviews in a loooong time at a foundational LLM company whose name I won’t reveal.
I will just say its name starts with "Liquid" and ends with "AI" and its goal is super simple:
"We cook the best small Language Models in the world, and we give you (my dear developer) the tools to customise these models for your use case and deploy them locally wherever you want: a phone, a car, a regular laptop, a robot, or a microwave, if talking to a food-heating device is your thing".
Now, every strong AI company out there these days has a long list of candidates to choose from. So, hiring processes have gotten quite tough.
One of the must-have stages in every tech role is the "technical stage(s)", consisting of
a technical interview, plus
a take-home project, plus
a pitch of the project you did
Two weeks ago I went through step 1, last week I did step 2 and this week I completed step 3.
Today I want to share with you how I prepared for the first step, so you can hopefully get insights and learnings you can apply to your own journey.
Let's start
What’s the challenge?
A technical interview is a live call with a senior engineer/tech lead. The goal at this stage is to assess your
technical literacy
experience and
mindset (super important!) to ramp up fast enough to be productive in the role.
It is not enough to know things "more or less". You need to understand the "why" and the "how" behind each algorithm, tool, trick or idea. You need breadth and depth.
In my case I had a deep dive interview on LLM post-training techniques with a very smart cookie named Edoardo Mosca (aka Edo).
Edo is also the name of the guy who gave this master lecture on the LLM Scaling Laws at the Technical University of Munich. I won't say they are the same person. But they are.
At this stage you are given two things:
A short amount of time to prepare for the interview —> 7 days in my case.
and
A topic —> LLM post-training techniques.
Now, "Post-training techniques for LLMs is a vaaast topic", that keeps on growing month by month with new research, papers and tools coming out from AI labs all over the world. I bet you will be facing a very similar situation in your next interview.
So, let me break it for you:
"You won't get to the interview knowing everything about the topic you are being interviewed on".
Nope. Simply you won't. And that's ok.
Because what you are being tested at this stage is not whether you know everything about the topic.
Knowledge is important, yes. But the capacity to reason, learn, zoom in, zoom out and synthetize is even more important. Companies (at least the smart ones) hire more for skills than for knowledge.
So, given this large pool of potential questions, and your limited time, what should you do?
My strategy
Think of the topic you need to explore as a map. A map you need to learn the best you can in a short amount of time.

In my case, I was lucky enough to be given a hint of the first topic we would discuss during our conversation (thanks Edo and Luke for that!).
The entry-point to the interview was Group Relative Policy Optimization (GRPO), which is one of the newest RL techniques to fine-tune LLMs that DeepSeek published less than a year ago.
Tip
Having the entrypoint to the conversation is a big big plus. So, if you are not give one, don't be afraid to ask for one.
Proactivity is ALWAYS a plus in a hiring process (and in life).
You will never be penalised for asking for a hint.
Now, you have a vast map to explore (e.g. LLM post-training techniques) and an entrypoint to the conversation (e.g. GRPO).
How do you proceed?

I recommend you go straight to the original source. In my case, I went to the original paper where DeepSeek presented GRPO to the world.
I read the paper from beginning to end, and at the end I tried to extract my own TLDR fromt he paper, which
went along the lines of:
GRPO is a Reinforcement Learning technique that DeepSeek developed to fine-tune LLMs to solve multi-step reasoning tasks using verifiable rewards.It was applied after the initial supervised fine-tuning stage using high quality annotated data, which is a standard step in the LLM fine-tuning pipeline.
As for its inner workings, it is a tweaked version of the Proximal Policy Optimization (PPO) algorithm, which OpenAI championed almost 10 years ago to solve multi-step decision-making tasks in highly dimensional action spaces. DeepSeek tweaked it to decrease the number of parameters to keep in memory, and make the algorithm train faster with less hardware resources.Of course you can ask ChatGPT to generate this, or an even better, TLDR from the paper. But that is NOT the point.
The point is, you need to go through the paper yourself, several times, to ingest and DIGEST its ideas.
Reading summaries it is great when you have the context, but it is not enough if you want to go deep into the details, which you definitely need in a technical interview.
From this starting point, I was able to draw the first diagram that gave me the framework I was looking for.
The super-simplified map of the LLM (pre and) post-training world.
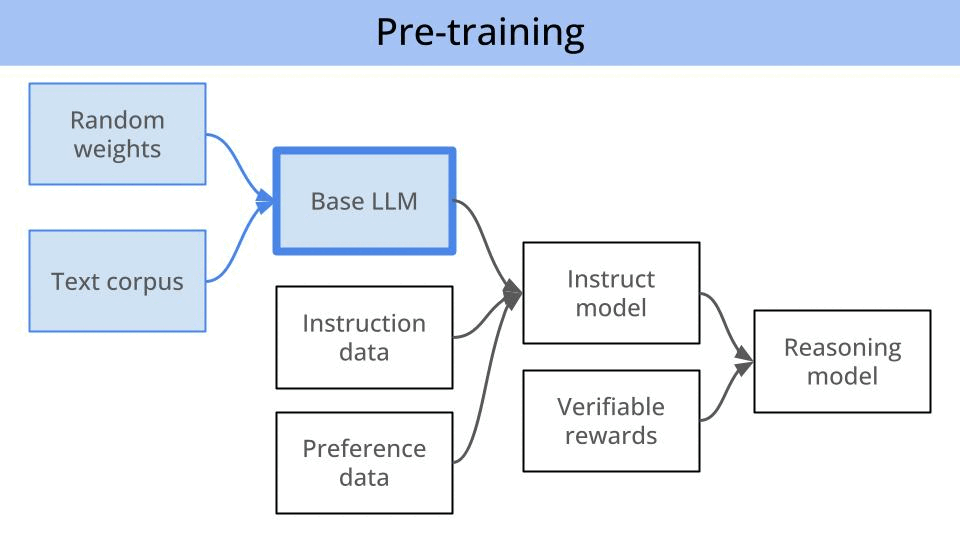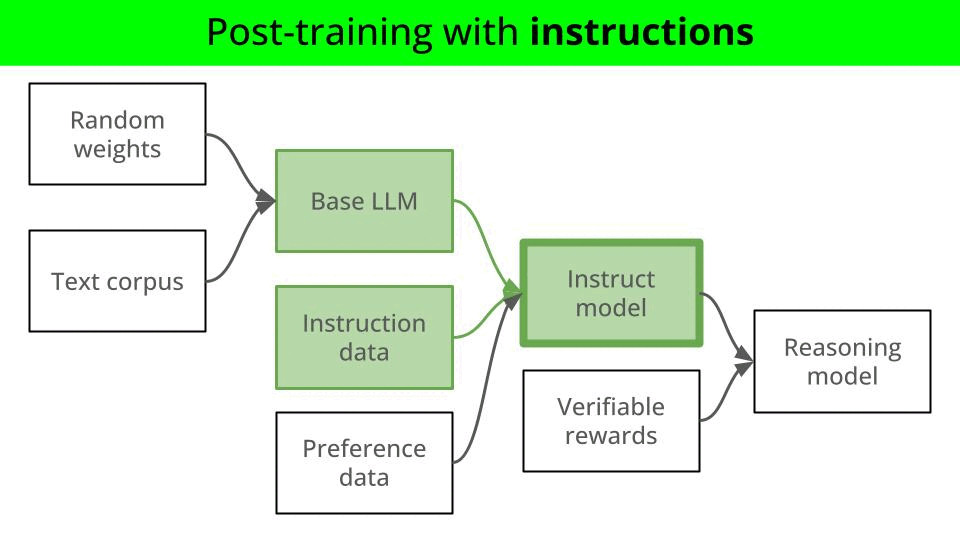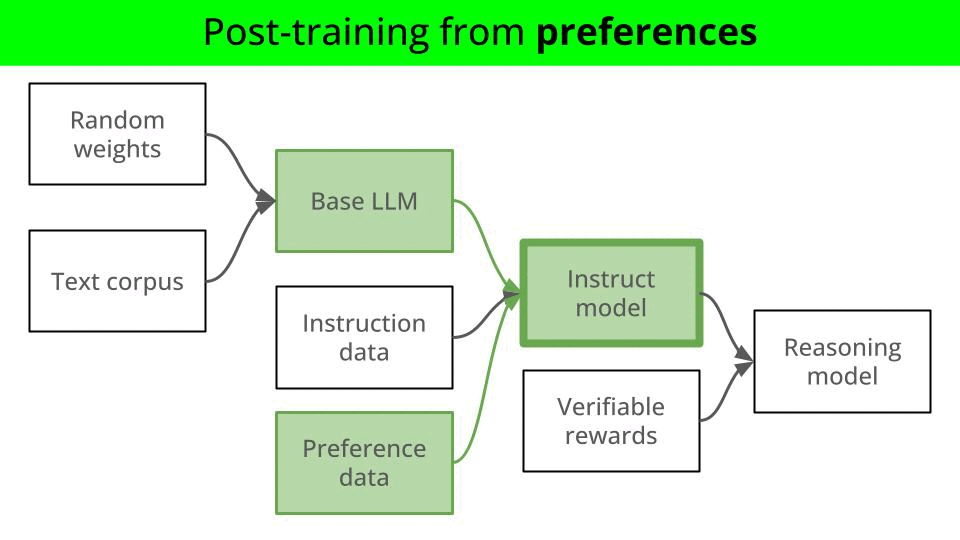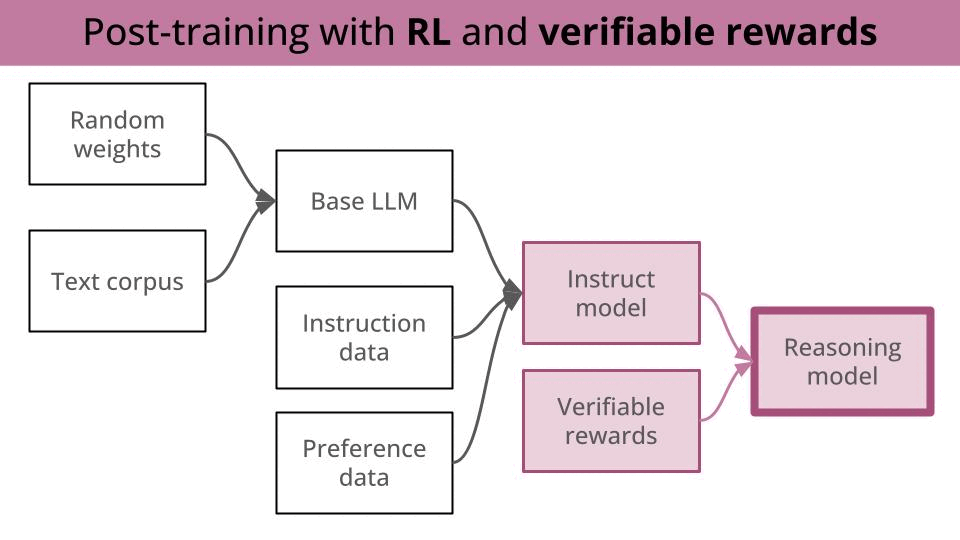
In a nutshell, LLMs go through several stages of training, commonly referred as
Pre-training, where a large corpus of data is used to train a next-word predictor model. A very few companies in the world pre-train LLMs from scratch, and Liquid AI is one of them.
Post-training with high quality instruction data (aka supervised fine-tuning)
Post-training with preference data (aka preference fine-tuning)
(optionally) Post-training with RL with verifiable rewards (e.g. GRPO) to equip the LLM with better multi-step reasoning capabilities.
From here, there are lots of natural follow-up questions you can ask yourself, like:
What does an instruction dataset look like? How can I build one?
What does a preference datataset look like? How can I build one?
Why RL, if supervised fine-tuning seems to be enough?
What is a verifiable reward? And a policy? And RL in general?
and blablabla
Now, if you have enough background you should be able to answer a few of them already. Like, for example, a few years ago I spent a few intense months learning and published a hands-on course on Reinforcement Learning, so the RL element in the mix was something I was familiar with, and had to dig just a little bit to feel confident.
As for the rest, I had a general idea but I needed a more systematic approach to cover each of the steps.
This is when I remembered about the excellent book that Maxime Labonne and Paul Iusztin published a few months ago, the LLM Engineer's Handbook.
The chapter that Maxime wrote on supervised-fine tuning data preparation, algorithms and preference alignment is a must-read for anyone looking to understand the post-training world of LLMs.
Maxime happens to be the name of the guy leading the post-training team at the company I am interviewing for. I won't say he is the same guy as the one who wrote the chapter, but they are.
I read the relevant chapters of the book from beginning to end, a couple of times. My goal was to have the whole thing in my brain, and from there start going deep into the details AND the implementation details.
AI is a super-mega-hyper applied thing. Of course you need to have the theoretical background, but unless you `uv init` from your terminal, and try to build the shit yourself, your knowledge will be as solid as thin air.
At this stage, I compiled a list of libraries, tutorials and papers and I started applying the knowledge I had been absorbing these past days, trying to build my own LLM chess player.
You can see the end result in this repository and read all the details in last week’s post.

Practicing with code is a great way to solidify your knowledge.
I have been saying this thing for YEARS. The only way to truly learn something is to build something with it.
Of course, time is limited and you should not aim to build a whole project during the interview preparation. But you need to get started.
At the end of the day, you need to be ambitious. You know that this round is just the next round, but after it there will be another one, where your actual coding skills will be tested.
And you will have (again) limited time to prepare for it.
So, go for it. Stamina, energy, consistency, grit, and the world is yours.
Now it is your turn
I hope you found this story useful.
If you did, please share it with your friends and colleagues.
And if you didn't, please let me know what you think.
I would love to hear from you.
And if you have any questions, please don't hesitate to ask.
I will be happy to help.
And before you leave… I have a free top-notch event for YOU
The Feature Store Summit 2025 is the global event for data engineers and ML engineers building AI systems.
Not theory. Just real-world engineering from folks building real-time, AI, LLM systems in top companies, including Uber, Coinbase, Lyft, Hopworks or EY.
The event is online, free to attend and starts on October 14th.

Talk to you next week,
Pau
Excellent as always.
You are lucky Pau to have 7 days to prepare. In US, you are expected to complete either an assessment test or take one of those insulting on-line timed coding tests. Plus tech economy is in the toilet.