
Wanna learn to deploy ML systems to production?
Kubernetes from day 1

This week I spent 9 hours coding live with my students of Building a Real Time ML System. Together.
It was super fun and intense, with lots of debugging, questions and nuggets of wisdom from an infra guru like Marius, and a bearded ML engineer called Pau.
At the end of the week, we managed to build two of the three services that make our feature pipeline and deploy them to a production Kubernetes cluster running on bare metal. Sexy.
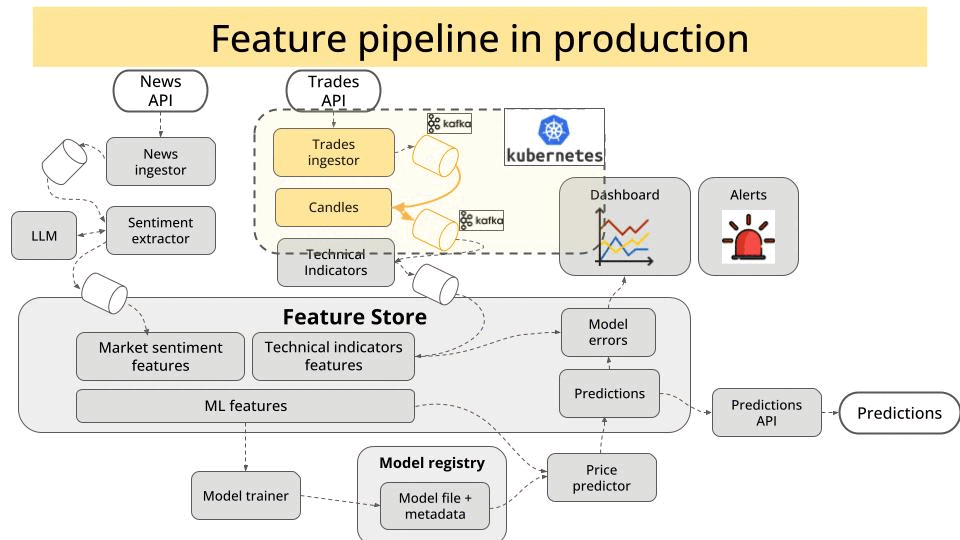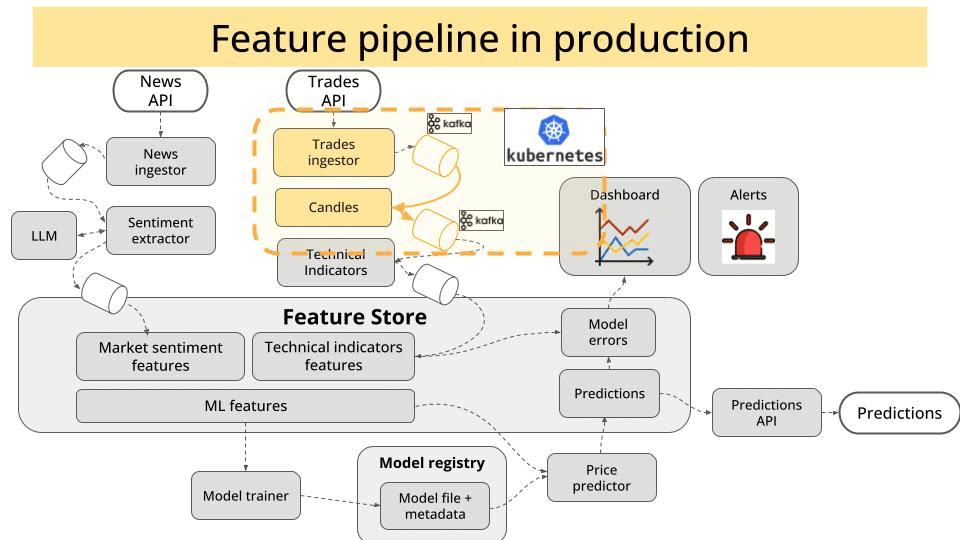
Why deploying from day 1?
Because companies do not care about ML toys running locally, no matter how fancy these toys are. They need
END-2-END SYSTEMS (yes, capital letters) that
run on their PRODUCTION ENVIRONMENTS (capital letters again) and
move business metrics (business metrics should also go in capital letters, but I think that would be too much for your eyes, wouldn’t it?)
Today I want to quickly explain what we did, and how we plan to take things to the next level.
Let’s go!
Deployments to Kubernetes 101
In my opinion, the easiest way to get familiar with Kubernetes is by running a local development cluster.
How to run Kubernetes locally?
Kind is a great tool for that.
Working locally with a kind Kubernetes cluster is a great way to get your hands-dirty using
the almighty kubectl command line interface, and
k9s, my favourite tool to inspect and navigate your entire Kubernetes cluster with a super stylish UI 😎
If you need a quick hands-on tutorial, check this previous article I wrote a few weeks ago ⬇️
Kubernetes for ML engineers
·Kubernetes is one of the hard skills you nonstop find in job descriptions for ML engineers.

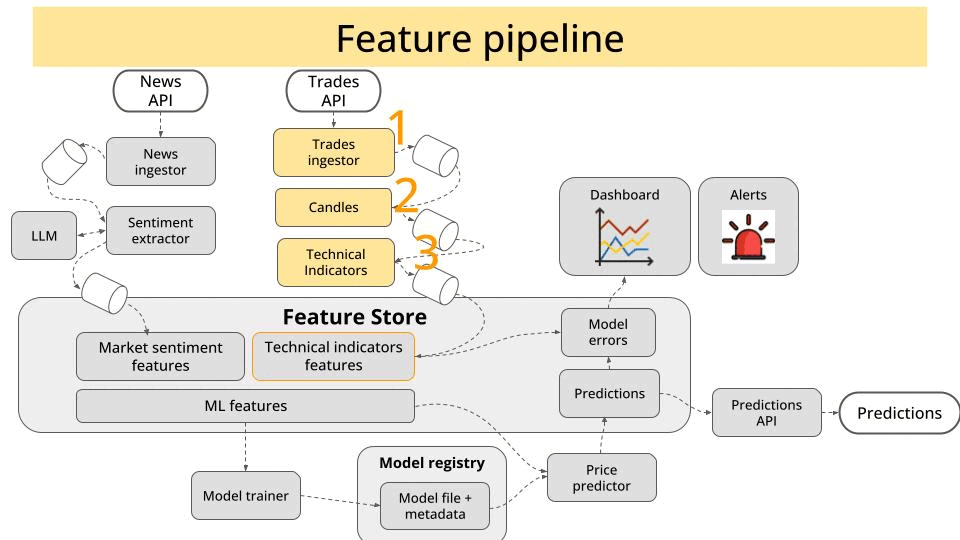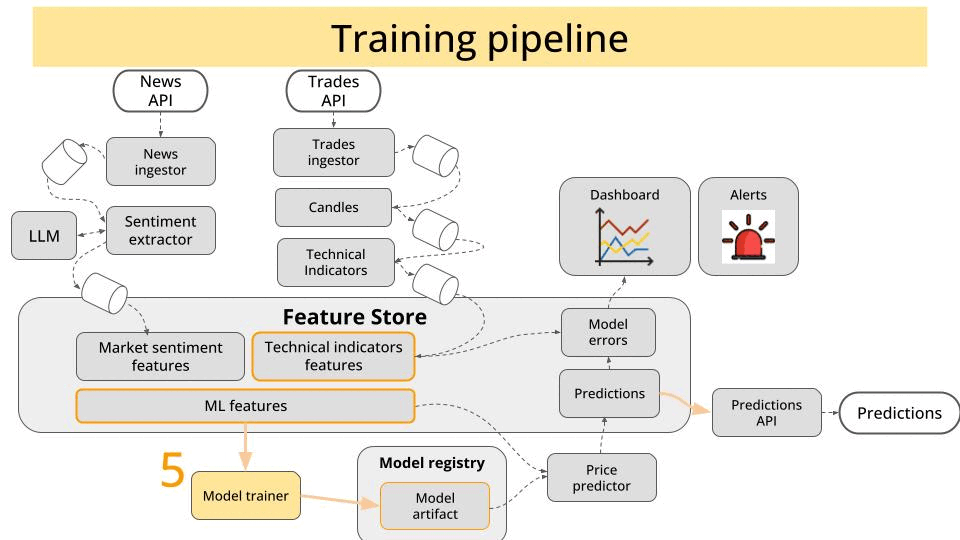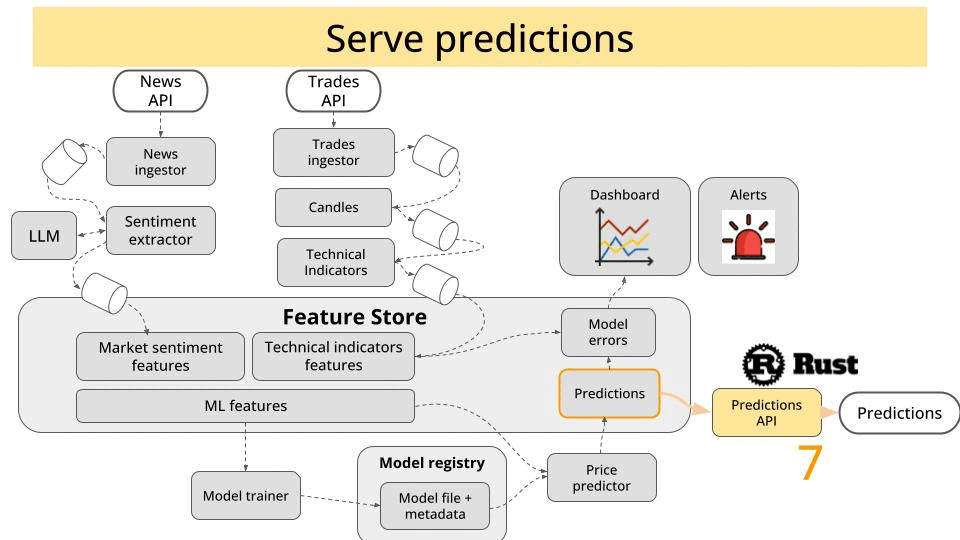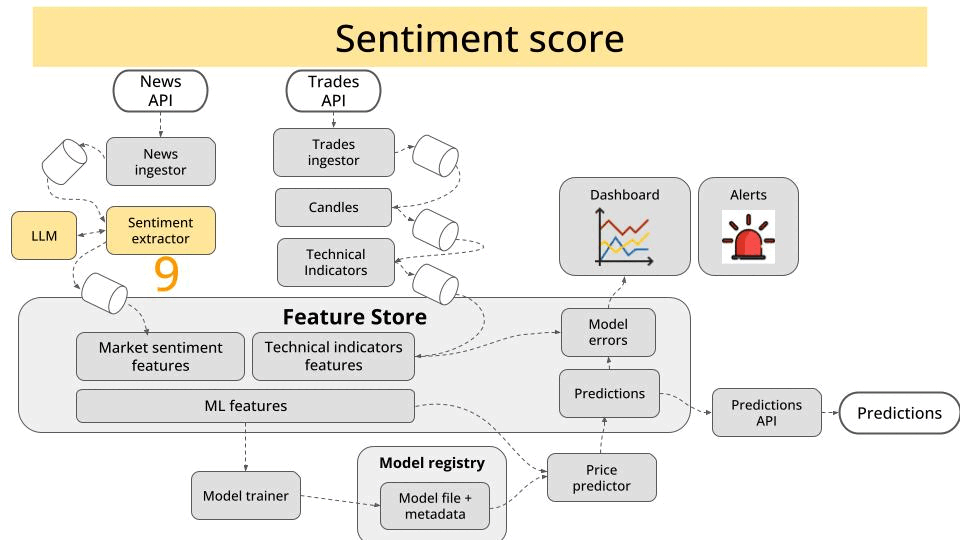
So, in the course we first built the 2 services:
The trade producer, that reads trades in real time from the Kraken exchange websocket API, and pushes them into a Kafka topic.
The candles service, that uses stateful stream processing to aggregate trades into 1-minute candles, and push them to another Kafka topic.

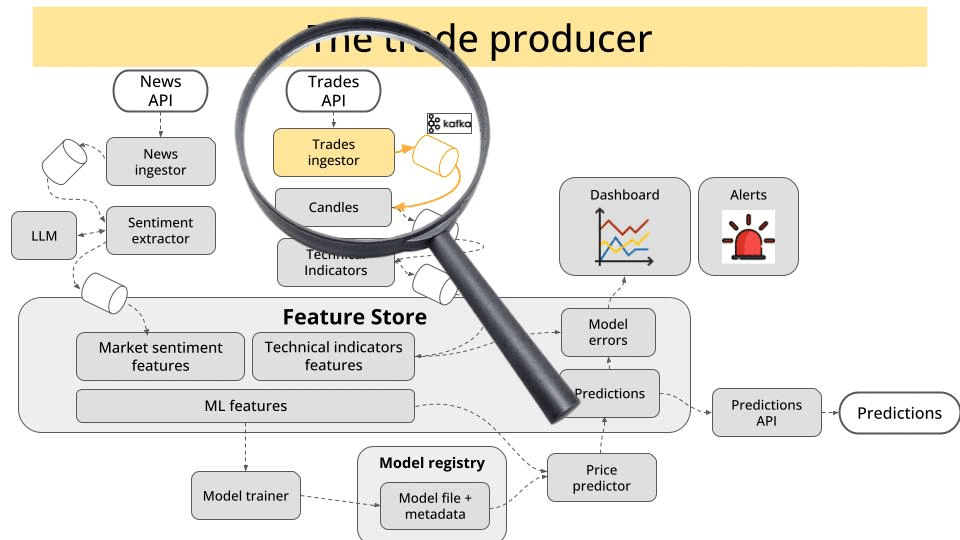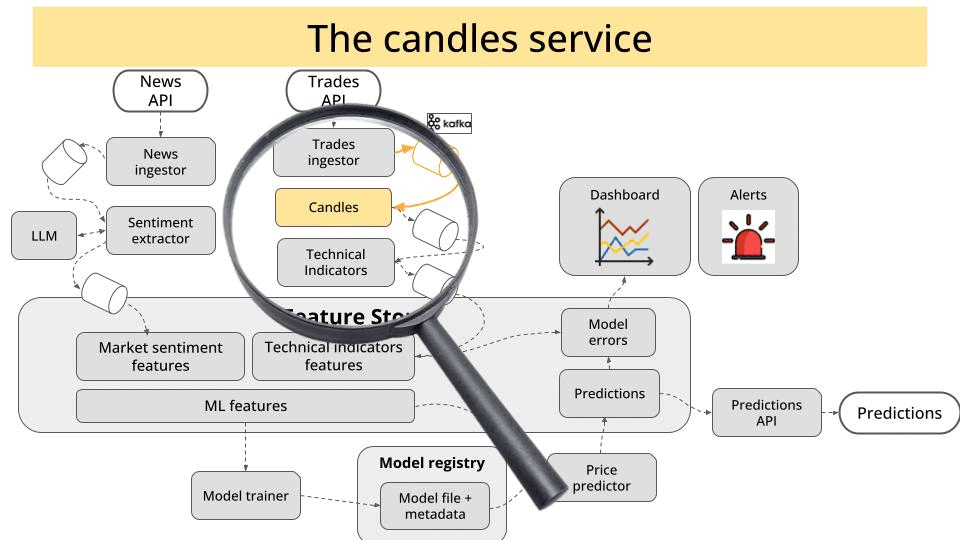
Tip 💡
The easiest way I know to work with a potentially large Python codebase like this is with uv workspaces. This is what we are doing in the course.
Once our Python code was ready, we wrote a Dockerfile for each service.
Not sure how to write a Dockerfile to containerise your apps?
Check this previous blog post, with a hands-on example
Let's write a professional Dockerfile
·Last week I showed you how to build a production-ready REST API using Python, FastAPI and Docker. And I promised you that today we would deploy it and make it accessible to the outside world.

Once our Dockerfiles were ready, we
Built the Docker images, using semantic versioning (thanks Marius for the tip), and cross-platform support (linux/amd64), and
Pushed them to the Github container registry of the course.
export BUILD_DATE=$(date +%s) && \
docker buildx build --push --platform linux/amd64 -t ghcr.io/real-world-ml/${service}:0.1.5-beta.${BUILD_DATE} -f docker/${service}.Dockerfile .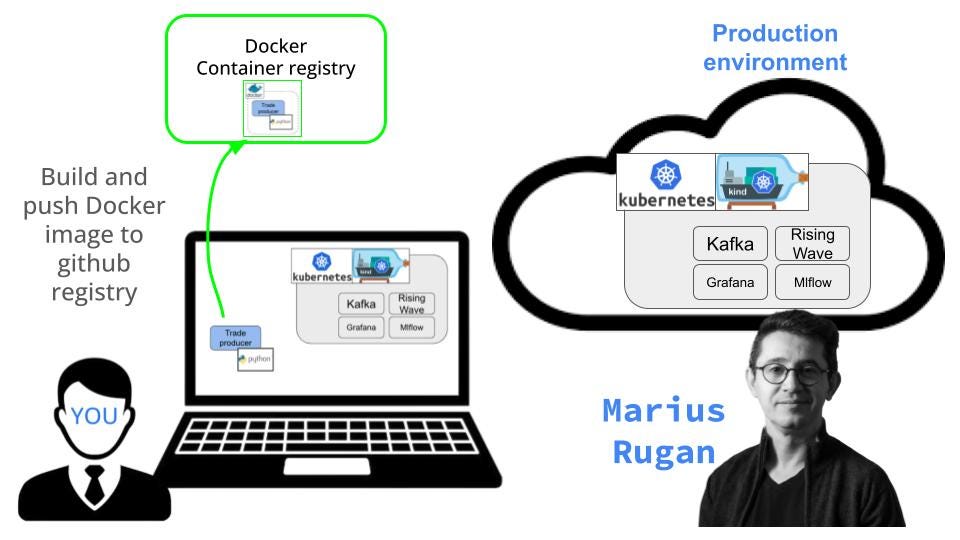
Once the images were on our container registry, we moved onto writing the deployment manifests for ours apps.
For example, this is what the deployment yaml of our candles service looks like:
# candles.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: candles
namespace: rwml
labels:
app: candles
spec:
replicas: 2
selector:
matchLabels:
app: candles
template:
metadata:
labels:
app: candles
spec:
containers:
- name: candles
image: ghcr.io/real-world-ml/candles:0.1.5-beta.@sha256:fb4a1683f1b18a59a2a62e68d0f221335691f96ed496e732886a5d9bc1fd48b9
imagePullPolicy: Always # Make sure we use the latest docker images fronm the github container registry, disregarding the caches images that kubernetes might have.
env:
- name: KAFKA_BROKER_ADDRESS
value: kafka-c6c8-kafka-bootstrap.strimzi.svc.cluster.local:9092
- name: KAFKA_INPUT_TOPIC
value: "trades"
- name: KAFKA_OUTPUT_TOPIC
value: "candles"
- name: KAFKA_CONSUMER_GROUP
value: "candles_consumer_group"
- name: CANDLE_SECONDS
value: "60"My 2 cents 🪙
I am not going to lie to you.
Kubernetes can be quite overwhelming, but when you overcome that initial shock, I promise you feel like the world is yours.
A magic and powerful collection of lego pieces that you can assemble to build ANY software, ML, LLM system you want.
ANY. I promise.
Ok, let’s go back to our deployment.
We have
the Docker image in the github container registry, and
the deployment yaml manifest ready.
It is not time for the final step, the `kubectl` magic.
$ kubectl apply -f deployments/prod/candles/candles.yaml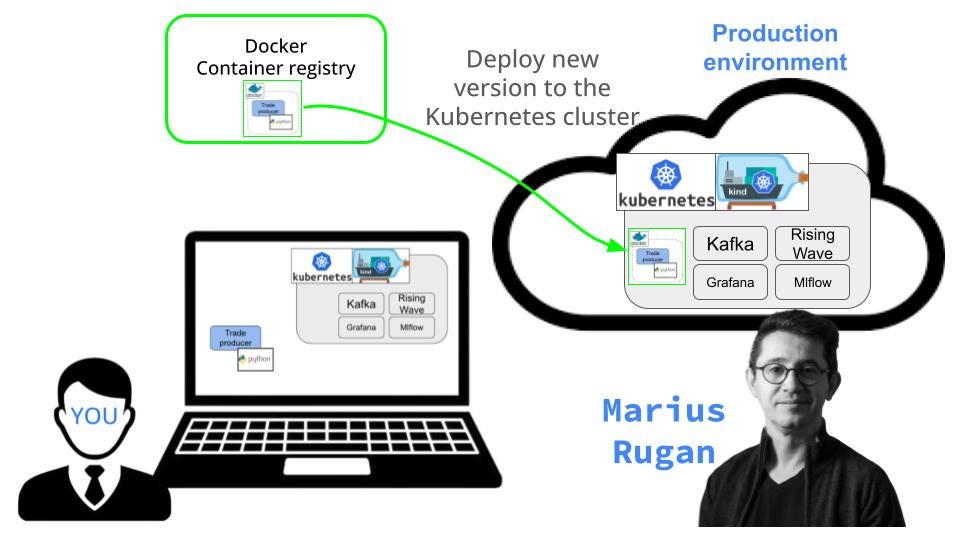
BOOM.
We have made it.
You have your code running in a production Kubernetes cluster.
What’s next?
This manual workflow is an eye opener the first time you try it.
But things can be done even better!
How?
Well, automating the deployments.
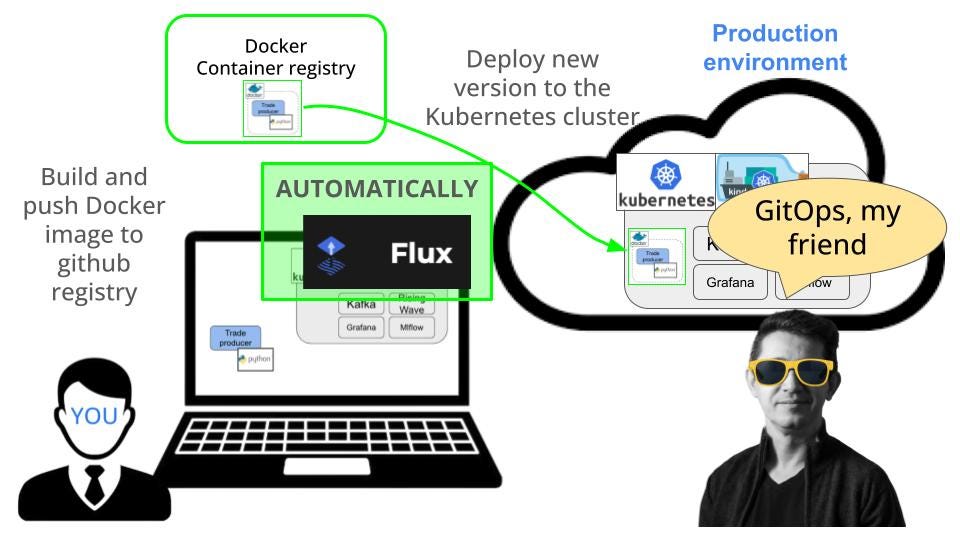
Using tools for continuous delivery like Flux, we will automate deployments, so we can focus on building our system logic.
Remember, we still have 12 more sessions and lots of pipelines, services and a couple of dashboards to build.
So we better get back to work!
Do you want to join this adventure?
The Discord community of the course is burning 🔥 with questions, hard-work, and a non-negligible amount of frustration. I get it, it is not an easy course. But hey. No pain, no gain.

Anyway, if your plan for the next year or so is to become really good at ML and LLM engineering, I think that joining this adventure is a great step towards that goal.
Every session is recorded from beginning to end (no edits) and uploaded once completed, so you can catch up with what we did, and follow at your own pace.
No Hype. No BS. Only the things that I have learned at work, and keep on learning every single day.
See you on the other side,
Pau
Amazing! Love this guys! Keep up the good work.
Was always frustrated by the fact that my models don’t end up being used and I knew the number one reason is the lack of MLOps skills to make them available to stakeholders in the first place. Thanks 🙏 for your time and effort in putting all this together!