
Real-time embeddings for LLM apps ⚡🤖

LLMs are as good as the data you embed in your prompts. And for many real-world problems, this means the data needs to be both
good, and
fresh
Example 💁
Imagine you build a great LLM-based financial advisor… but you only feed it with outdated data.
No matter how good your model is, the predictions it will generate will be rubbish 🫣
So, the question is
How do you ensure your LLM has access to fresh data ❓
The solution 🧠
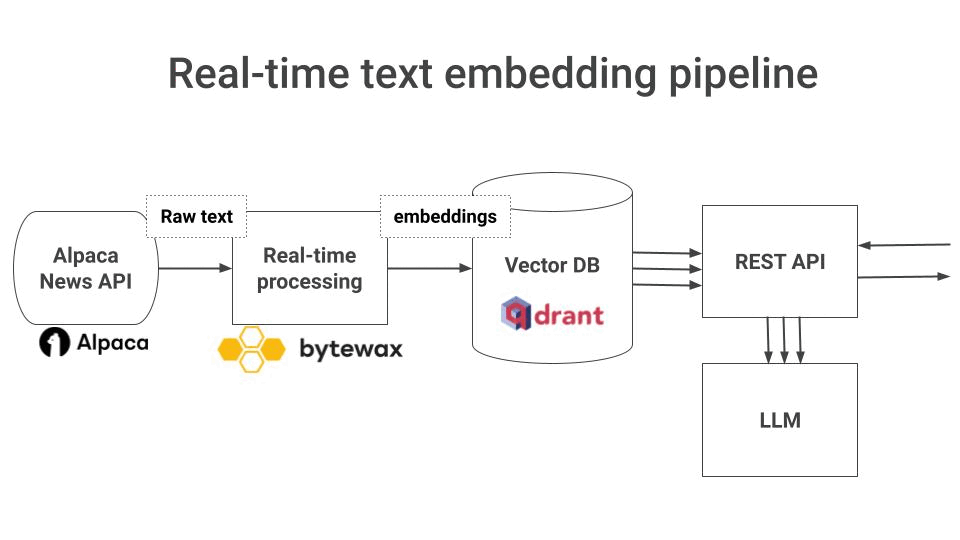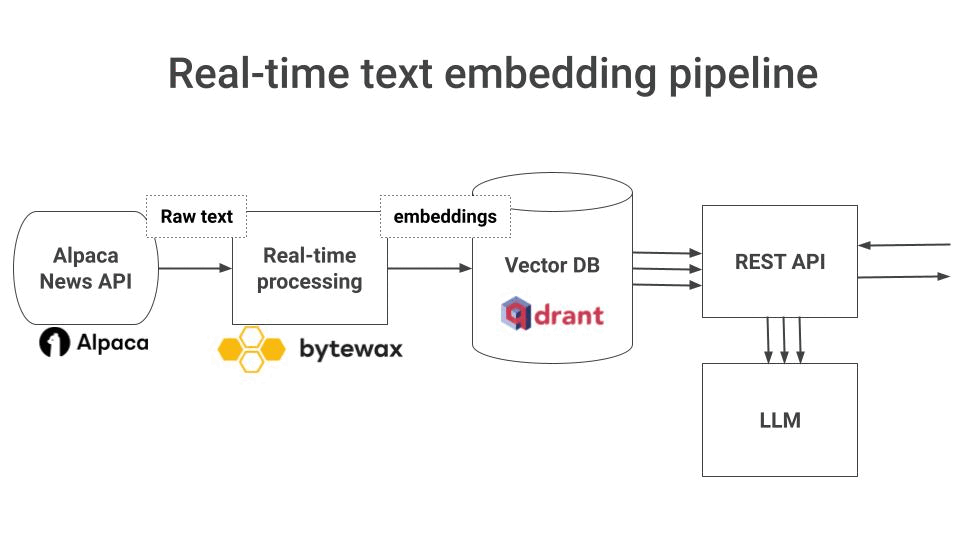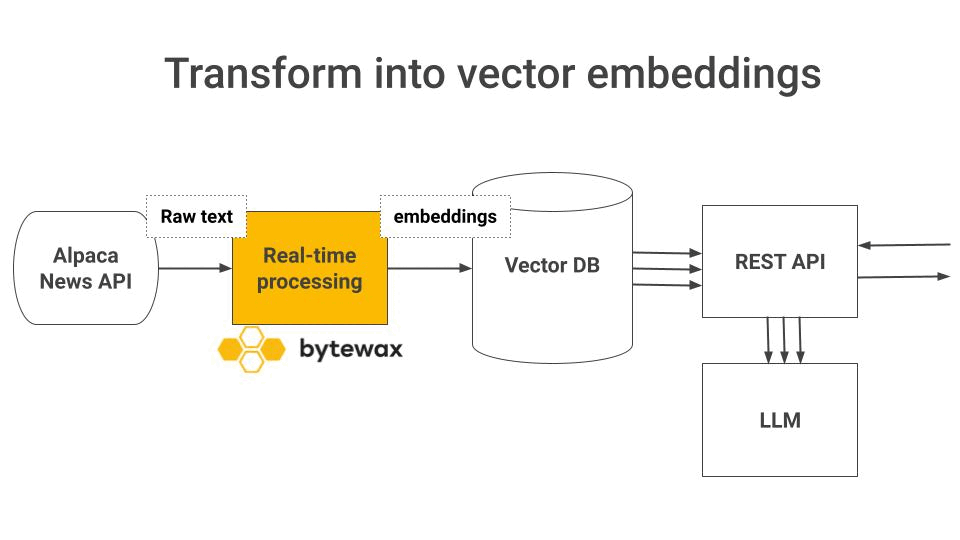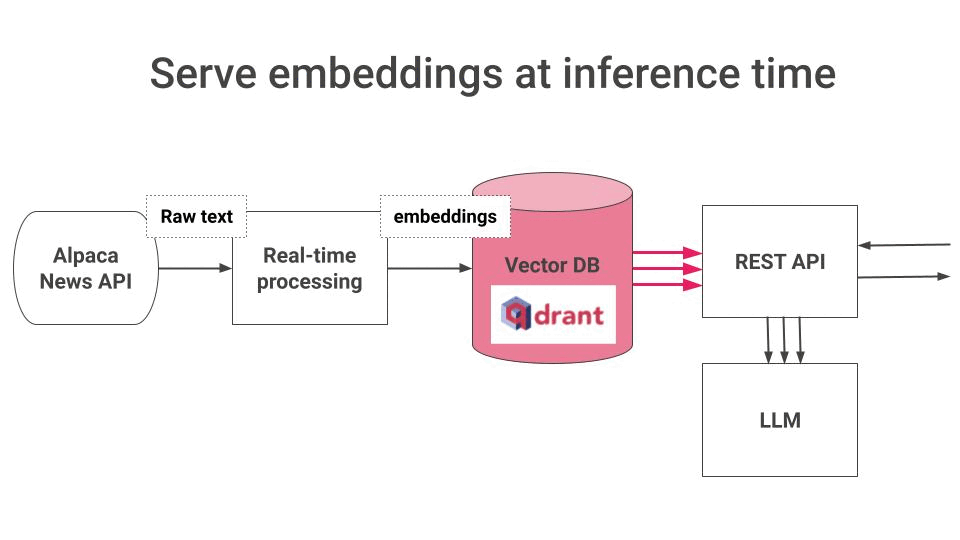
You need to build a real-time text embedding pipeline, that
Continuously ingests raw text from your data source, in real-time
Transforms this raw text into vector embeddings, and
Stores these embeddings in a VectorDB, so your LLM can fetch and use them for Retrieval Augmented Generation (RAG) at inference time.
Example with full source code 👨🏻💻
In Lesson 3 of the Hands-on LLM course, you will find a full source code implementation of a real-time text embedding pipeline in Python 🐍, for a financial advisor robot.
In this case, we use
Alpaca News API as our real-time data source,
Bytewax to transform raw text into vector embeddings, and
Qdrant as a Serverless Vector DB, to store and retrieve embeddings at inference time.
Video lecture 🎬
Click below to watch the lecture ↓↓↓
Join the Real-World ML Youtube channel
👉🏽 Subscribe to the Real-World ML Youtube channel for more hands-on FREE tutorials like this
See you on Youtube.
Enjoy the weekend,
Pau