
Real-time data for your LLM

The output of a Large Language Model is as good as the input prompt you send to the model.
Now, what makes a good prompt?
Prompt ingredients 🍱
A prompt is a string that blends 2 things:
A prompt template to condition the model towards the specific task we want to accomplish.
Contextual information the model needs to generate good output for our task, that we embed in the prompt template.
Example
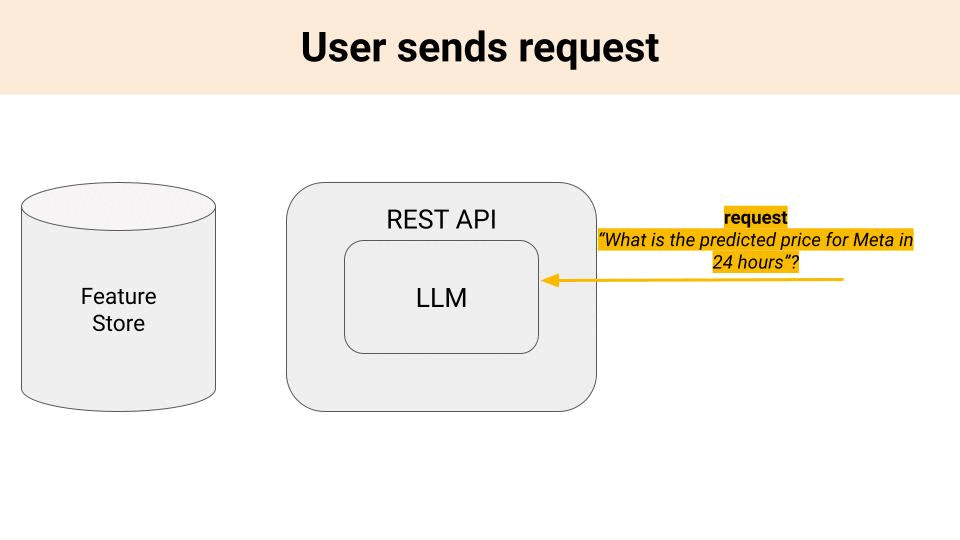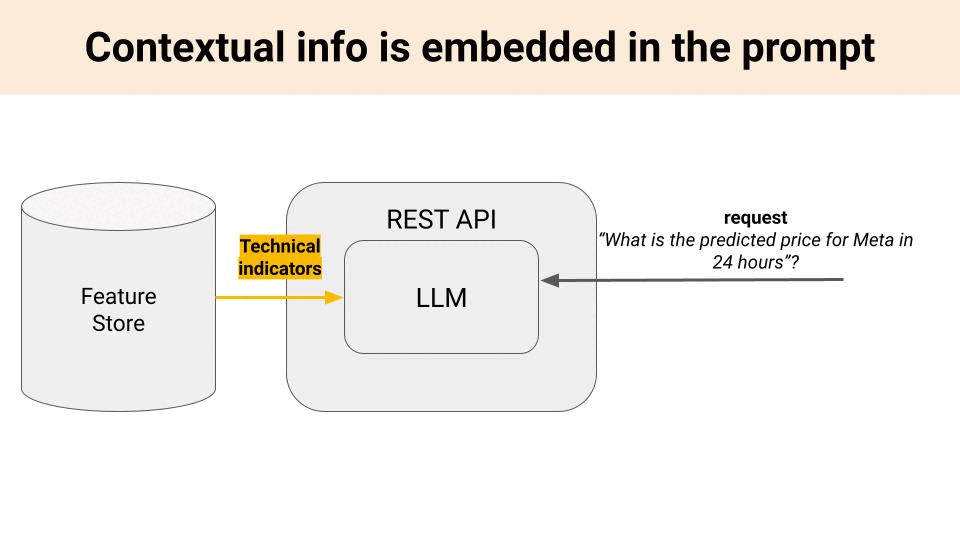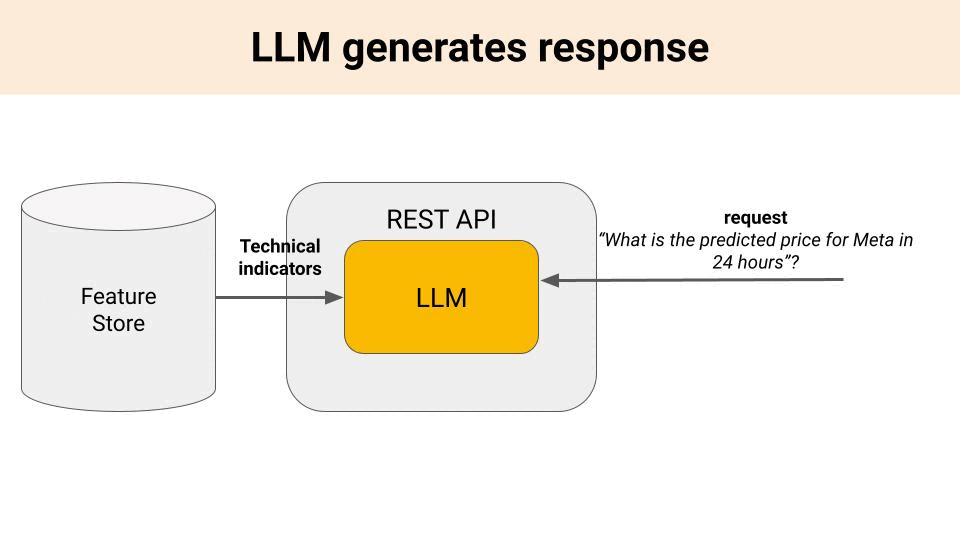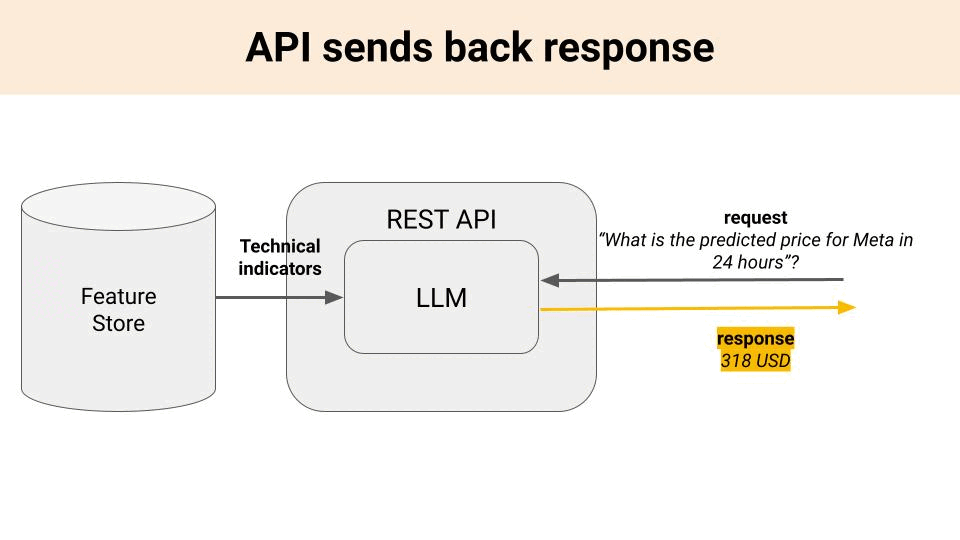
Let’s say you want to build a stock predictor using LLMs, and deploy it as a REST API. The model will take in a user input request like
“What is the predicted price for Meta in 24 hours”?
and return a price prediction.

And the thing is, no matter how good your LLM is, you will get bad predictions unless you embed contextual information, like
→ quantitative information, e.g. current price, price momentum, volatility or moving average.
→ qualitative information, e.g. recent financial news related to Meta.
in your prompt template.
For example:
prompt_template = “““
You are an expert trader in the stock market. I will give you a set of technical indicators for a given stock, and relevant financial news, and I want you to generate a price prediction for the next 24 hours. I want you to be be bold, and provide a numeric price prediction, and justify your prediction based on the technical indicators and news I provided.## Technical indicators
{QUANTITATVE_INFORMATION}
## News
{QUALITATIVE_INFORMATION}
What is the predicted price and your explanation for it?
“““
The question is then, where is this quantitative and qualitative information coming from?
Real-time ML to the rescue ⚡
To generate up-to-date real-time information you need 2 things:
1 → A storage and serving layer for these information, which is either a Feature Store or a Vector DB, depending on your use case, and
2 → A real-time feature pipeline, that listens to an incoming information stream (e.g. a websocket of stock prices), generate features (e.g. price technical indicators) and stores them in the storage layer (Feature Store or VectorDB).
This way, your system naturally decomposes into independent 2 pipelines, that can be managed by different teams.
→ The inference pipeline
→ The real-time feature pipeline
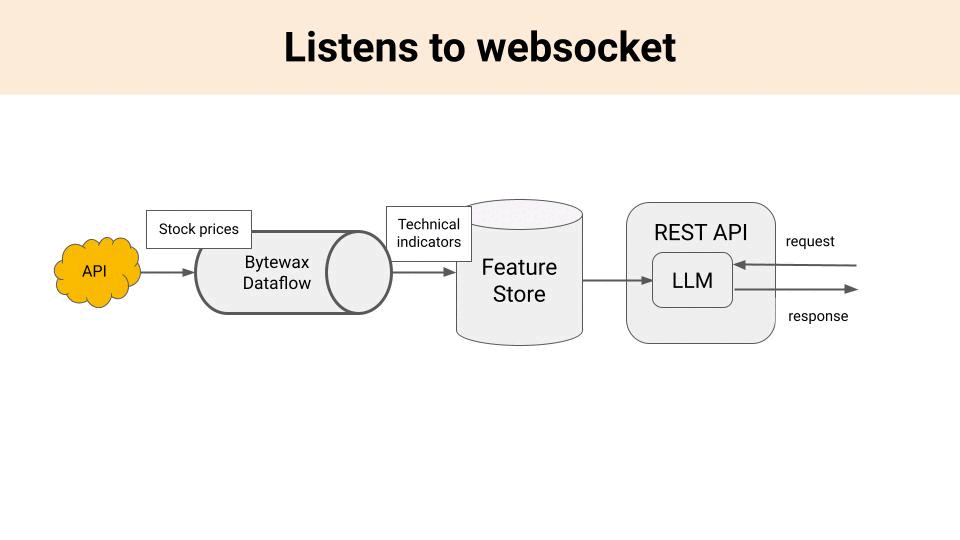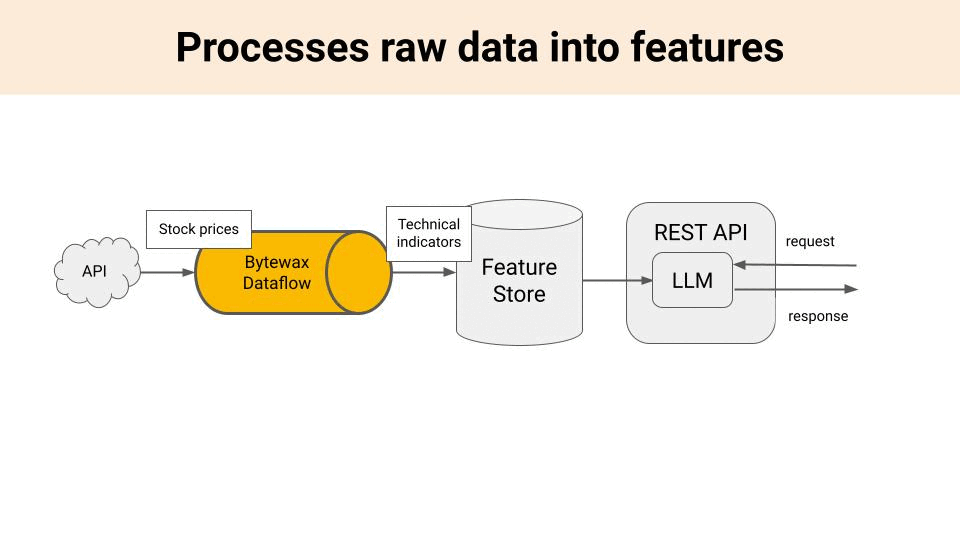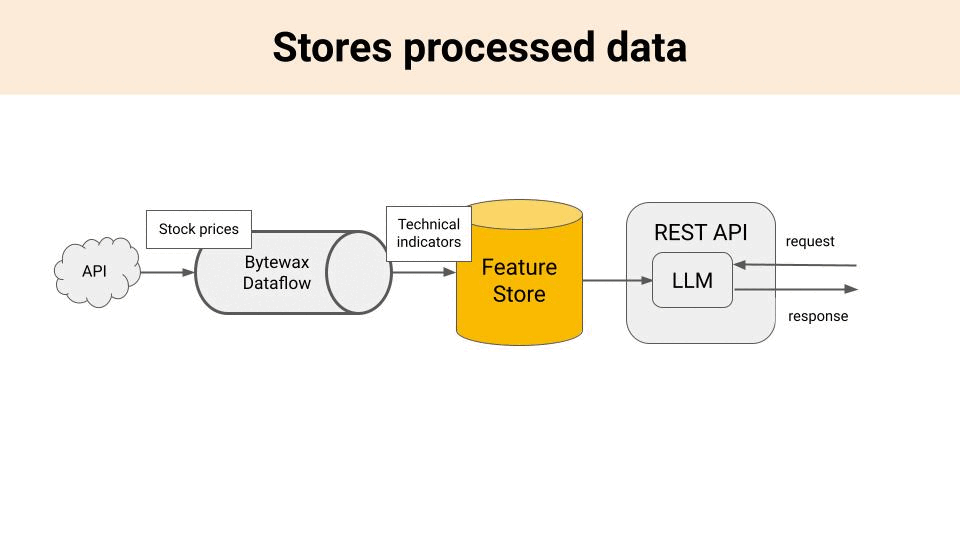
How do you build a feature pipeline?
Python alone is not a language designed for speed 🐢, which makes it unsuitable for real-time processing. Because of this, real-time feature pipelines were usually writen with Java-based tools like Apache Spark or Apache Flink.
However, things are changing fast with the emergence of Rust 🦀 and libraries like Bytewax 🐝 that expose a pure Python API on top of a highly-efficient language like Rust.
So you get the best from both worlds.
Rust's speed and performance, plus
Python vast ecosystem of libraries.
Full source example
In this repository, you will find a fully working implementation of a modular real-time feature pipeline using Python and Bytewax. Enjoy it, and give it a star ⭐ on GitHub if you found it useful
Let’s go real time! ⚡
The only way to learn real-time ML is to get your hands dirty.
→ Go pip install bytewax
→ Support their open-source project and give them a star on GitHub ⭐ and
→ Start building 🛠️
Talk to you next Saturday.
Let’s keep on learning,
Peace and Love
Pau
Another great article Pau!