
How to deploy a real-world LLM app

Large Language Models, like any other ML model, have 0 business value until you deploy them, and make their outputs accessible to end-users or other downstream services.
And the thing is, deploying LLMs is especially challenging due to their size and hardware requirements.
Today, I want to share with you the recipe to move your LLM model prototypes to production.
Let’s start!
Step-by-step deployment
These are the steps to move your LLM model artifact, that your fine-tuning pipeline generated, into a production LLM-based REST API:
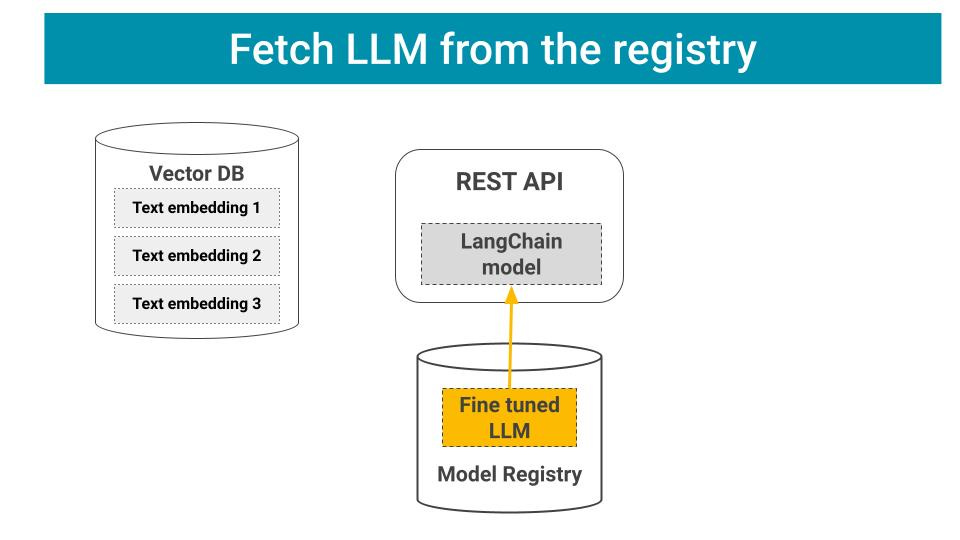
1️⃣ Push the LLM artifact to the model registry
The model registry is the place where you log your model arfifact, so the REST API can load it once, and re-use it across requests:
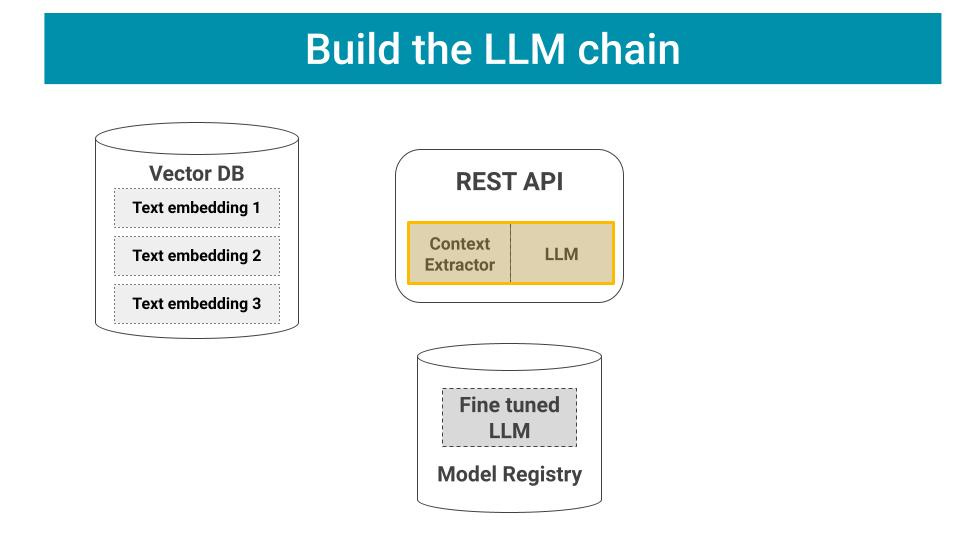
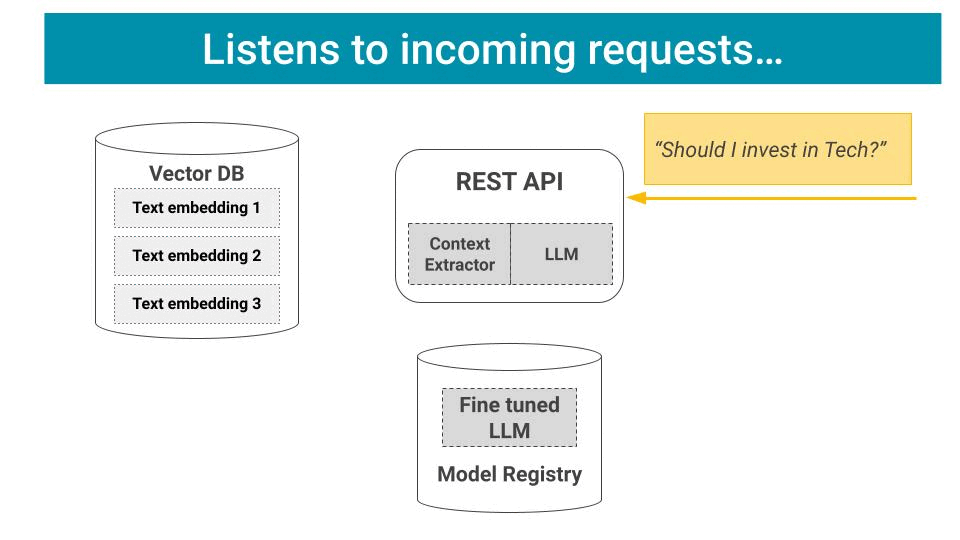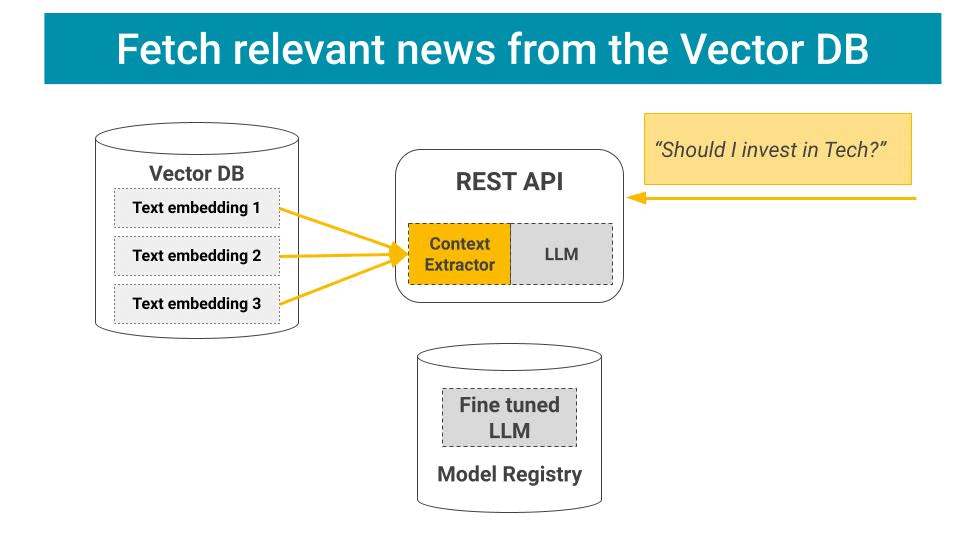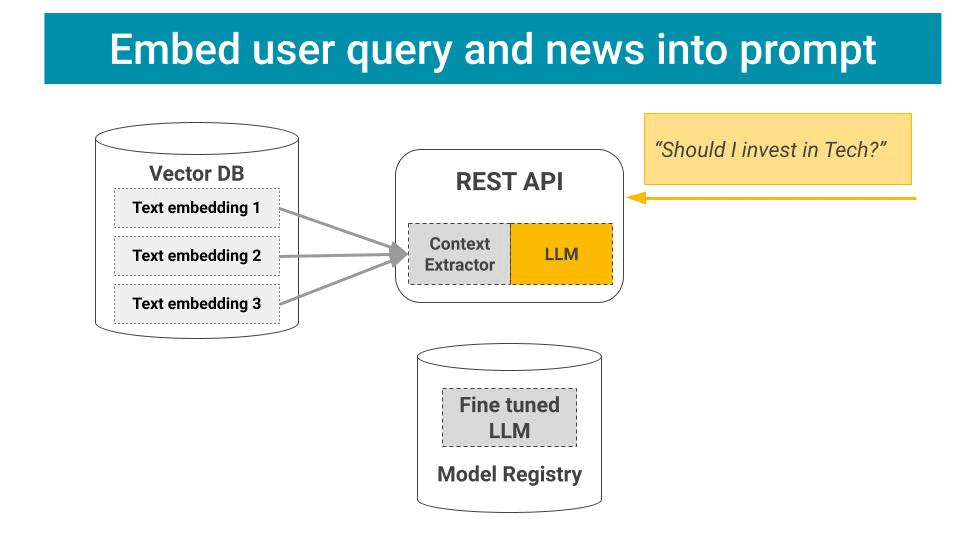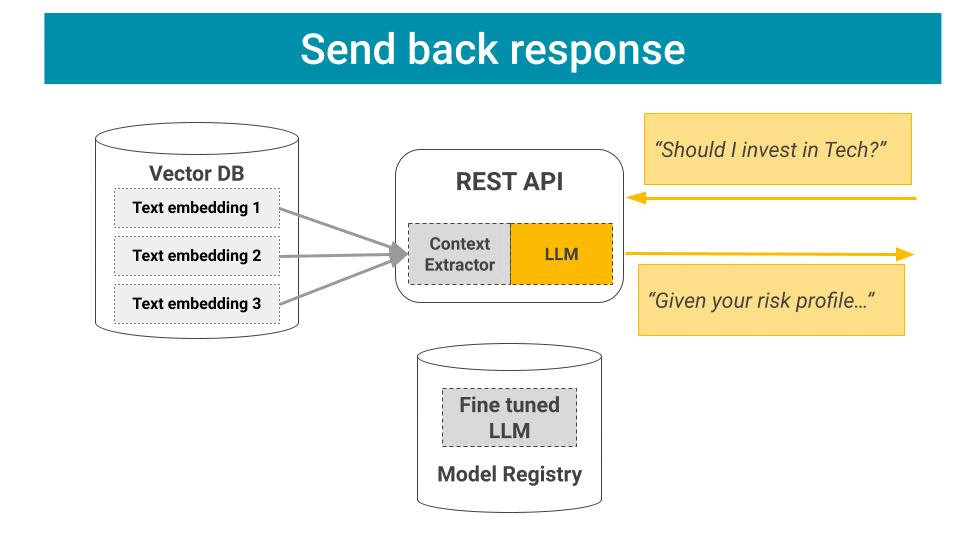
2️⃣ Wrap your LLM into a LangChain
Your LLM alone is not enough to perform the full mapping from user input to system response. For example, in a Retrieval Augmented Generation (aka RAG) your REST API needs to:
Fetch relevant context from your Vector DB.
Generate an enriched prompt, that contains the original user request, plus the context you extracted, and then
Pass this as input to your LLM
Moreover, you often want to perform post-processing steps to guarantee your final outputs conforms to some predefined format, e.g. JSON.
Standard library to build such chain are LangChain or Llamaindex.
3️⃣ Deploy your REST API to a GPU-enabled computing platform
To run your LLM at inference time you NEED AT LEAST ONE GPU. These models are heavy, and prohibitively slow for real-world applications if you do not parallelize computations with the help of a GPU.
Once the app is up and running, it can
Listen to incoming user requests
Process them through the LLM chain, and
Send back responses.
Tip ✨
I recommend you log every incoming request, chain inputs and outputs, and any other relevant metadata, for example, latency and cost, if you call an external API like OpenAI. This way you can track performance of your app and optimize it.
Here is an example 🎬
In the latest lecture of the Hands-on LLM Course that
, and myself have open-sourced, you will find a full source code implementation of an inference pipeline, using a 100% Serverless stack:CometML as model registry and CometLLM as prompt logging tool.
Qdrant as the VectorDB, and
Beam as the compute engine where we deploy the REST API.
Click below to watch the lecture 🎬 ↓↓↓
Wanna support this FREE course? → Give it a star ⭐ on Github
Wanna access more free hands-on lectures like this?
👉🏽 Subscribe to the Real-World ML Youtube channel for more hands-on FREE tutorials like this
Let’s keep on building.
Let’s keep on learning.
Pau