


Feature engineering in real-time with Kafka, Docker and Python

Read on realworldml.xyz
Let me show you step-by-step how to do feature engineering in real-time using Apache Kafka, Docker and Python.
The problem
Feature engineering is about transforming raw data into predictive signals for your Machine Learning model.
And for many real-word problems, you need to run this transformation in real-time. Otherwise, your features will be irrelevant.
For example 💁
Imagine you build a Machine Learning model that can predict stock price changes in the next 1-minute, but the input features the model needs are computed with an 1-hour delay.
No matter how good your model is, the whole system will NOT work 😔
So, as a professional ML engineer, you need to go beyond static CSV files and local Jupyter notebooks, and learn the tools that help you build production-ready real-time systems.
Let’s go through a step-by-step example.
Wanna get more real-world ML(Ops) videos for FREE?
→ Subscribe to the Real-World ML Youtube channel ←
Hands-on example 👩💻🧑🏽💻
Let me show you how to build a real-time feature-engineering service that
reads raw crypto-trade data from a Kafka topic (input topic),
transforms this raw data into Open-High-Low-Close features using stateful window aggregations, and
saves the final features into another Kafka topic (output topic), so the data is accessible to downstream services.
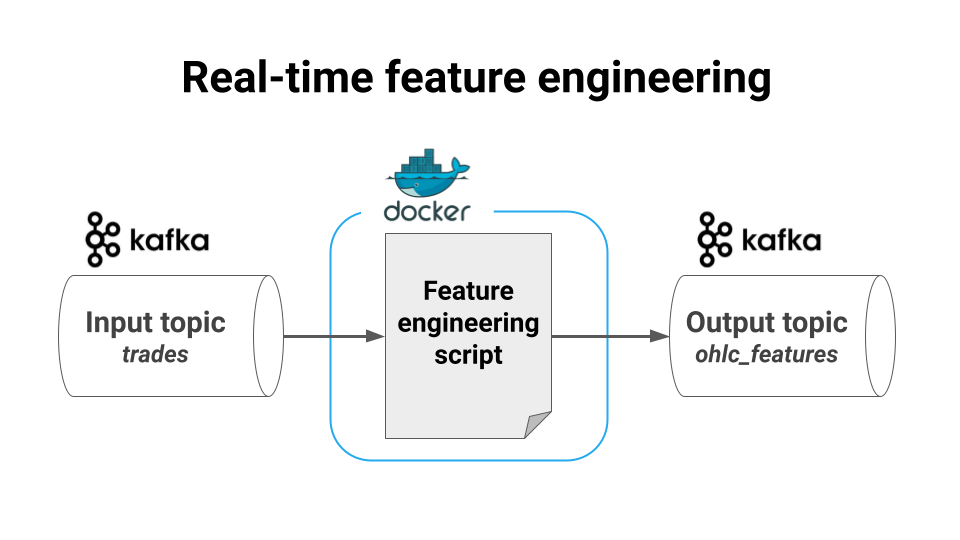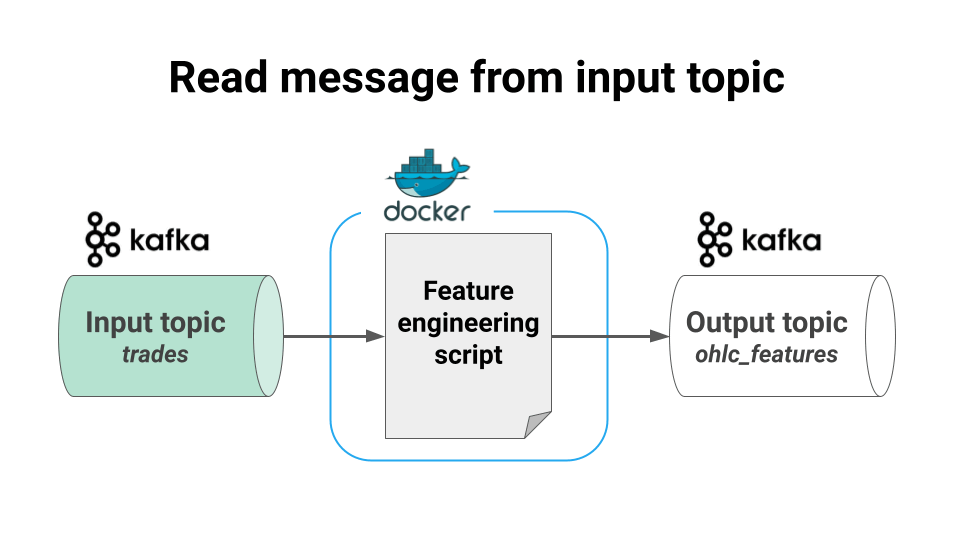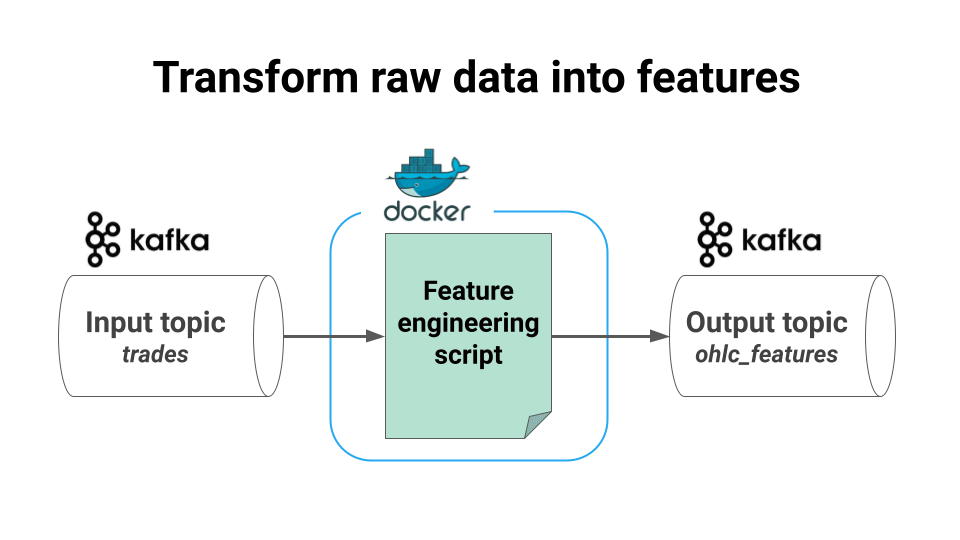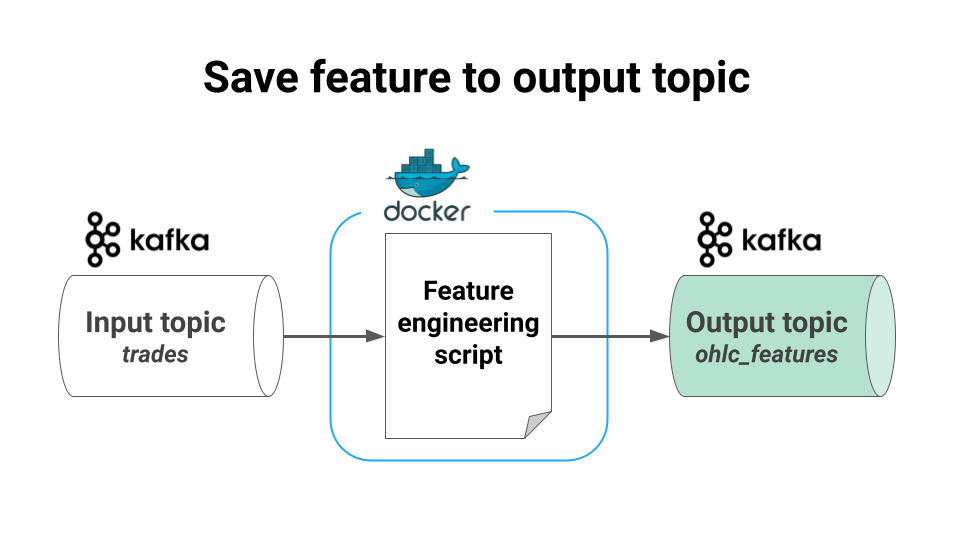
These are the tools we will use to build this:
Python Poetry to package our Python code professionally 😎
Quix Streams to do window aggregations in real-time ⚡
Docker to containerize our service, and ease the deployment to a production-environment 📦
Docker Compose to test things out locally.
A Kafka message broker, in this case Redpanda, to enable communication between our service and the rest of the infrastructure.
Steps
You can find all the source code in this repository
→ Give it a star ⭐ on Github to support my work 🙏
These are the 4 steps to build a real-time feature-engineering service.
Step 1. Create the project structure
We will use Python Poetry to create our ML project structure. You can install it in your system with a one-liner.
$ curl -sSL https://install.python-poetry.org | python3 -Once installed, go to the command line and type
$ poetry new trade_to_ohlc --name srcto generate the following folder structure
trade_to_ohlc
├── README.md
├── src
│ └── __init__.py
├── pyproject.toml
└── tests
└── __init__.pyThen type
$ cd trade_to_ohlc && poetry installto create your virtual environment and install your local package src in editable mode.
Step 2. Start a local Kafka cluster with Docker Compose
To develop and run our feature engineering service locally we first need to spin up a local lightweight Kafka cluster.
And the simplest-most-straight-forward way to do so is to use Docker an Redpanda.
What is Redpanda? 🟥🐼
Redpanda is a Kafka API-compatible data streaming platform, written in C++, that eliminates most of the of complexities that the original Apache Kafka has, while improving performance.
To spin up a minimal Redpanda cluster with one broker you add this docker-compose.yml
version: '3.7'
name: ohlc-data-pipeline
services:
redpanda:
container_name: redpanda
image: docker.redpanda.com/redpandadata/redpanda:v23.2.19
...
console:
container_name: redpanda-console
image: docker.redpanda.com/redpandadata/console:v2.3.8
...
depends_on:
- redpandaNow go to the command line and start your local Redpanda cluster by running
$ docker compose up -dCongratulations! You have a Redpanda cluster up and running.
It is time to focus on the feature engineering logic.
Step 3. Feature engineering script
Our script needs to do 3 things:
Read input data from a Kafka topic,
Transform this data into OHLC features, and
Save the final data into another Kafka topic.
And the thing is, you can do the 3 things in Python using the Quix Streams library.
Install the Quix Streams library inside your virtual environment
$ poetry add quixstreamsAnd create a new Python file to define your feature engineering
dashboard
├── README.md
├── main.py
├── src
│ └── __init__.py
├── pyproject.toml
└── tests
└── __init__.pyInside this main.py file you
Create a Quix Application, which will handle all the low-level communication with Kafka for you.
from quixstreams import Application app = Application( broker_address=os.environ["KAFKA_BROKER_ADDRESS"], consumer_group="json__trade_to_ohlc_consumer_group" )Define the input and output Kafka topics of our application
input_topic = app.topic('raw_trade', value_deserializer="json") output_topic = app.topic('ohlc', value_serializer="json")Define you feature engineering logic, in this case we use 10-second window aggregations, using a Pandas-like API.
# Create your Streaming data frame sdf = app.dataframe(input_topic) # 10-second window aggregations sdf = sdf.tumbling_window(timedelta(seconds=WINDOW_SECONDS), 0) \ .reduce(reduce_price, init_reduce_price) \ .final()Produce the result to the output topic
sdf = sdf.to_topic(output_topic)Start processing incoming messages with
app.run(sdf)
If you now run your feature engineering
$ poetry run python main.py
...
INFO:quixstreams.app:Waiting for incoming messagesyour script will just hang, waiting for incoming messages to arrive from Kafka.
Why there are no incoming messages? 🤔
Simply because there is no data in the input Kafka topic “trades”.
To fix this you can either
Write a second script that dumps mock raw data into the topic, or
Use the actual service that will generate production raw data.
In this case, I opted for 2, and here you can find the complete implementation of the trade producer service.

Step 4. Dockerization of our service
So far you have a working feature engineering service locally. However, to make sure your app will work once deployed in a production environment, like a Kubernetes Cluster, you need to dockerize it.
For that, you need to add a Dockerfile to your repo
trade_to_ohlc
├── Dockerfile
├── README.md
├── main.py
├── poetry.lock
├── pyproject.toml
├── src
│ └── ...
└── tests
└── __init__.pywith the following layered instructions
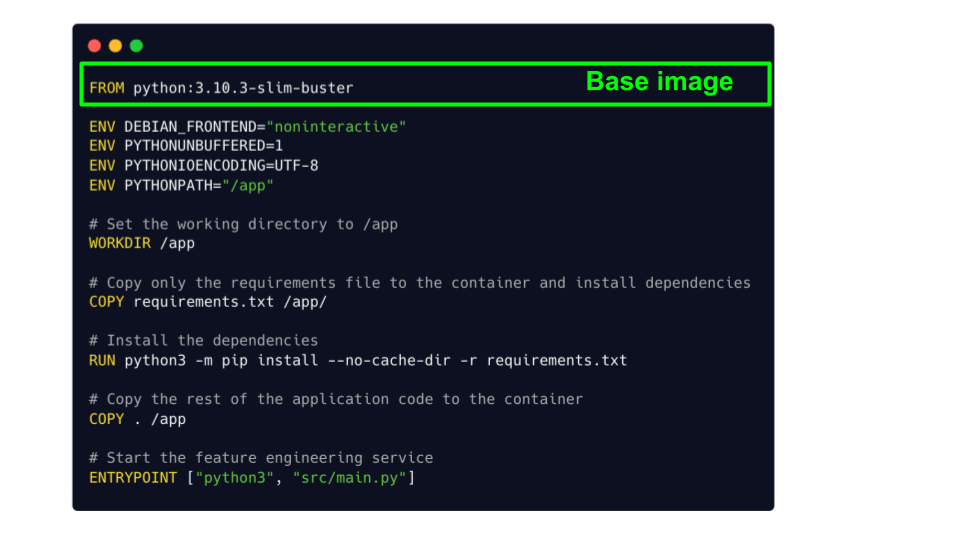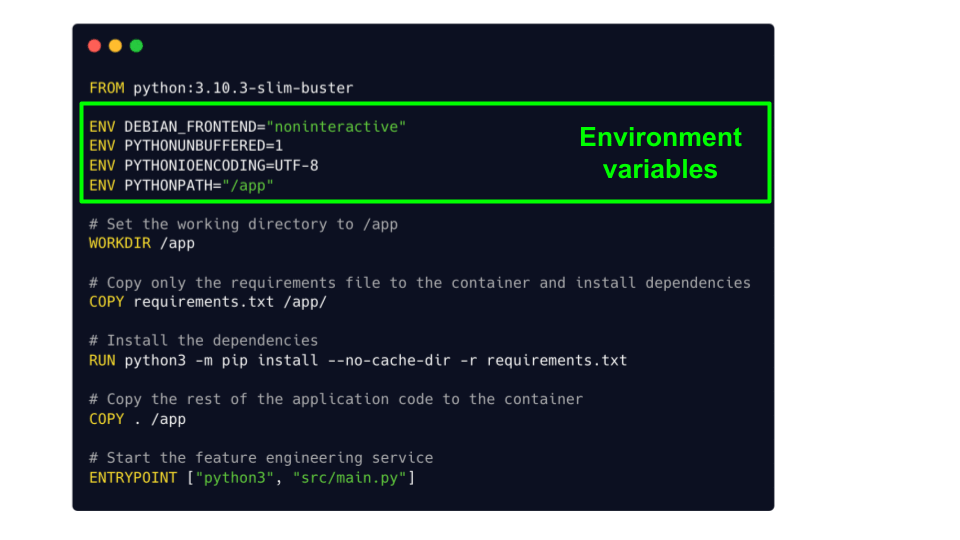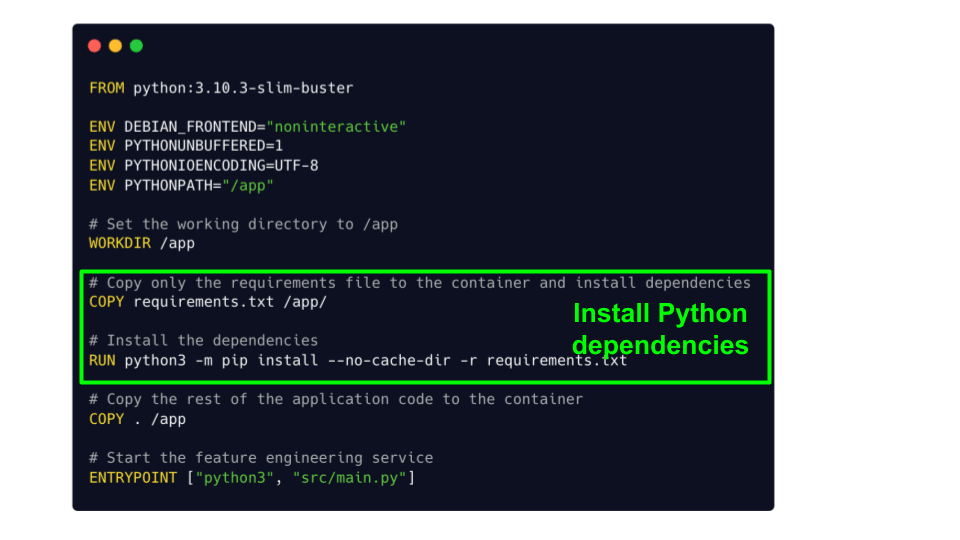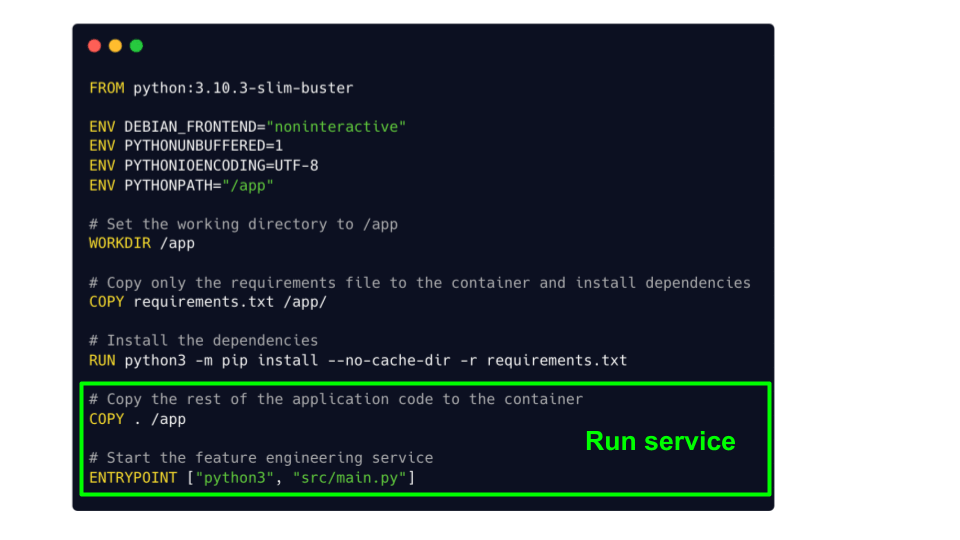
From this Dockerfile you can build your Docker image
$ docker build -t ${DOCKER_IMAGE_NAME} .and run the container locally
$ docker run ${DOCKER_IMAGE_NAME}Another way to spin up your service is to add it to your docker-compose.yml file, together with the trade producer service.
version: '3.7'
name: ohlc-data-pipeline
services:
redpanda:
container_name: redpanda
image: docker.redpanda.com/redpandadata/redpanda:v23.2.19
...
console:
container_name: redpanda-console
image: docker.redpanda.com/redpandadata/console:v2.3.8
...
depends_on:
- redpanda
trade-producer:
container_name: trade-producer
restart: always
build:
context: "./trade_producer"
...
depends_on:
- redpanda
trade-to-ohlc:
container_name: trade-to-ohlc
restart: always
build:
context: "./trade_to_ohlc"
...
depends_on:
- redpandaNow go to the command line and run everything with
$ docker compose up -dCongratulations! You have a production-ready real-time feature engineering script up and running.
Now it’s your turn 🫵🏻
The only way to learn ML is to get your hands dirty.
So, go to the Github repo I created, git clone it, and adjust it for your problem.
And remember,
No pain. No gain.
Let me know in the comments if something is not clear.
Wish you a good weekend.
Love, Laugh and Health.
Pau